王珊、萨师煊《数据库系统概论》考研考点讲义.pdf
- 文件大小: 12.14MB
- 文件类型: pdf
- 上传日期: 2025-08-25
- 下载次数: 0
概要信息:
目 录
第一章 绪论 (1)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第二章 关系数据库 (20)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第三章 关系数据库标准语言SQL (36)
!!!!!!!!!!!!!!!!!!!!!!!!!
第四章 数据库安全性 (60)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第五章 数据库完整性 (70)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第六章 关系数据理论 (78)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第七章 数据库设计 (98)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第九章 关系查询处理和查询优化 (122)
!!!!!!!!!!!!!!!!!!!!!!!!!
第十章 数据库恢复技术 (131)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第十一章 并发控制 (141)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第十二章 现代数据库 (155)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
第一章 绪论
第1讲 数据库系统概述
第一部分 知识点回顾
1.1 数据库系统概述
1.1.1 四个基本概念
·数据(Data)
·数据库(Database)
·数据库管理系统(DBMS)
·数据库系统(DBS)
1、数据
数据(Data)是数据库中存储的基本对象
数据的定义:描述事物的符号记录
数据的种类:文本、图形、图像、音频、视频、学生的档案记录、货物的运输情况等
数据的特点:数据的含义称为数据的语义,数据与其语义是不可分的
2、数据库
数据库的定义:数据库(Database,简称DB)是长期储存在计算机内、有组织的、可共享的大量数据
的集合。
数据库的基本特征:
·数据按一定的数据模型组织、描述和储存
·可为各种用户共享
·冗余度较小
·数据独立性较高
·易扩展
3、数据库管理系统
DBMS:位于用户与操作系统之间的一层数据管理软件;是基础软件,是一个大型复杂的软件系统
DBMS的用途:科学地组织和存储数据、高效地获取和维护数据
DBMS的主要功能:
·数据定义功能
—1—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
提供数据定义语言(DDL)
定义数据库中的数据对象
·数据组织、存储和管理
分类组织、存储和管理各种数据
确定组织数据的文件结构和存取方式
实现数据之间的联系
提供多种存取方法提高存取效率
·数据操纵功能
提供数据操纵语言(DML)
实现对数据库的基本操作(查询、插入、删除和修改)
·数据库的事务管理和运行管理
数据库在建立、运行和维护时由 DBMS统一管理和控制保证数据的安全性、完整性、多用户对
数据的并发使用发生故障后的系统恢复
·数据库的建立和维护功能(实用程序)
数据库初始数据装载转换
数据库转储
介质故障恢复
数据库的重组织
性能监视分析等
·其它功能
DBMS与网络中其它软件系统的通信
两个DBMS系统的数据转换
异构数据库之间的互访和互操作
1.1.2 数据管理技术的产生和发展
数据管理:
·对数据进行分类、组织、编码、存储、检索和维护
·数据处理的中心问题
数据管理技术的发展过程:
·人工管理阶段(20世纪40年代中———50年代中)
·文件系统阶段(20世纪50年代末———60年代中)
·数据库系统阶段(20世纪60年代末———现在)
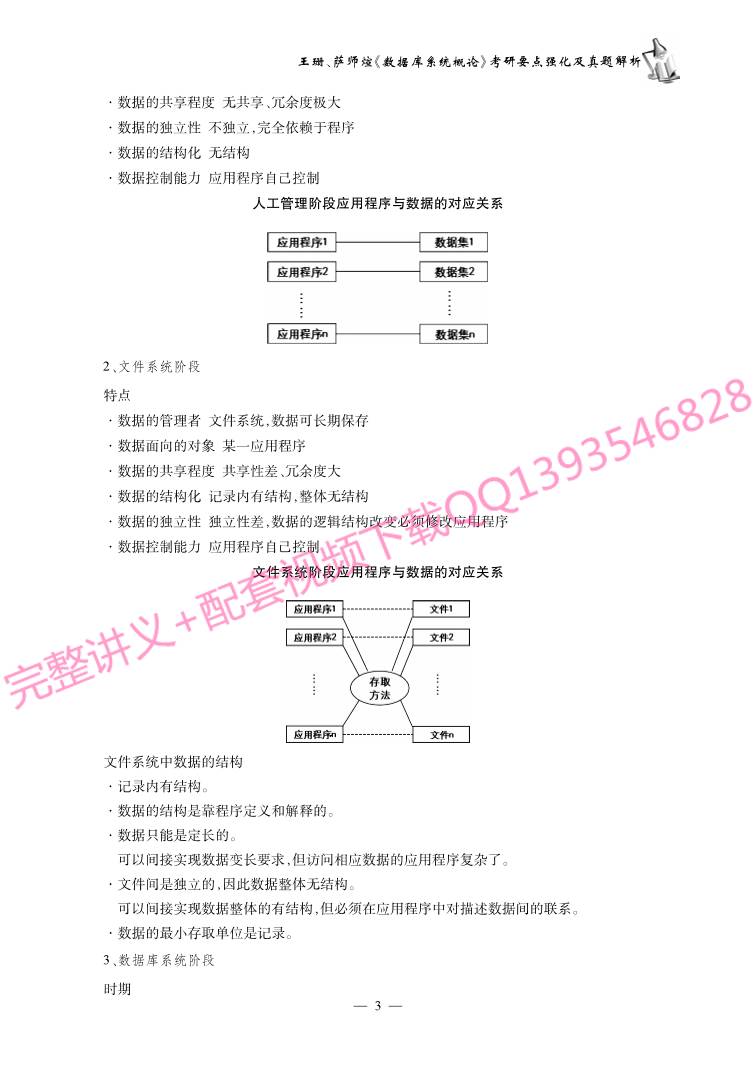
1、人工管理阶段
特点:
·数据的管理者:用户(程序员),数据不保存
·数据面向的对象:某一应用程序
—2—
·数据的共享程度:无共享、冗余度极大
·数据的独立性:不独立,完全依赖于程序
·数据的结构化:无结构
·数据控制能力:应用程序自己控制
人工管理阶段应用程序与数据的对应关系
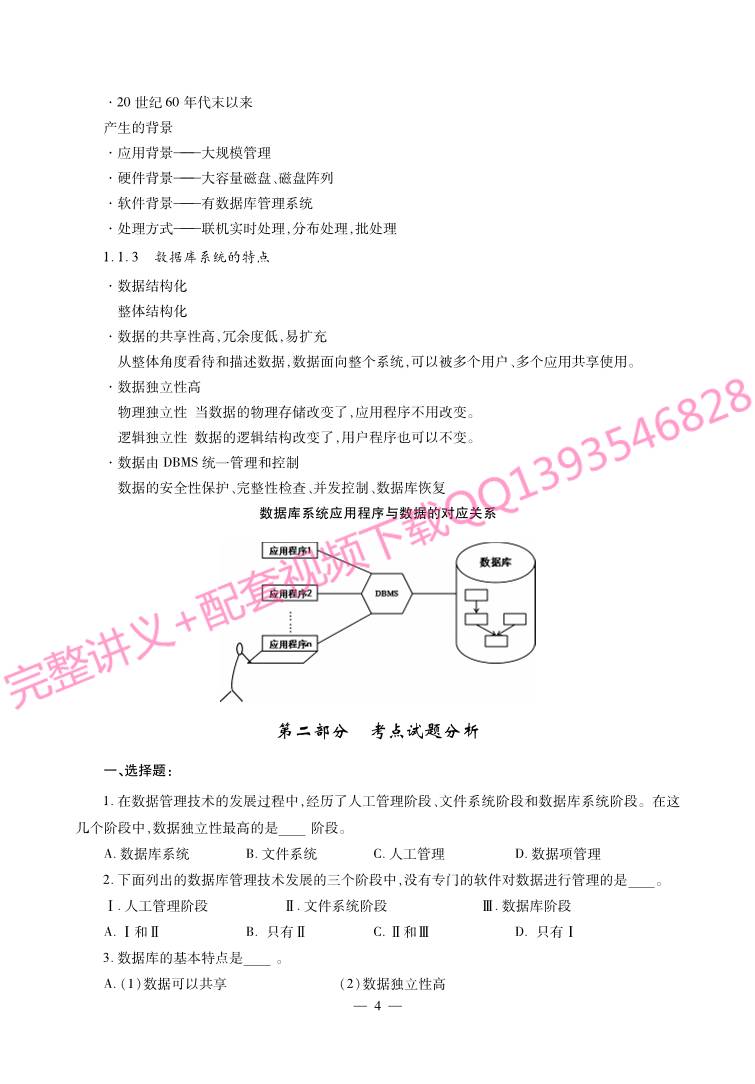
2、文件系统阶段
特点:
·数据的管理者:文件系统,数据可长期保存
·数据面向的对象:某一应用程序
·数据的共享程度:共享性差、冗余度大
·数据的结构化:记录内有结构,整体无结构
·数据的独立性:独立性差,数据的逻辑结构改变必须修改应用程序
·数据控制能力:应用程序自己控制
文件系统阶段应用程序与数据的对应关系
文件系统中数据的结构
·记录内有结构。
·数据的结构是靠程序定义和解释的。
·数据只能是定长的。
可以间接实现数据变长要求,但访问相应数据的应用程序复杂了。
·文件间是独立的,因此数据整体无结构。
可以间接实现数据整体的有结构,但必须在应用程序中对描述数据间的联系。
·数据的最小存取单位是记录。
3、数据库系统阶段
时期:
—3—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·20世纪60年代末以来
产生的背景:
·应用背景———大规模管理
·硬件背景———大容量磁盘、磁盘阵列
·软件背景———有数据库管理系统
·处理方式———联机实时处理,分布处理,批处理
1.1.3 数据库系统的特点
·数据结构化:
整体结构化
·数据的共享性高,冗余度低,易扩充:
从整体角度看待和描述数据,数据面向整个系统,可以被多个用户、多个应用共享使用。
·数据独立性高:
物理独立性:当数据的物理存储改变了,应用程序不用改变。
逻辑独立性:数据的逻辑结构改变了,用户程序也可以不变。
·数据由DBMS统一管理和控制
数据的安全性保护、完整性检查、并发控制、数据库恢复
数据库系统应用程序与数据的对应关系
第二部分 考点试题分析
一、选择题:
1.在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。在这
几个阶段中,数据独立性最高的是 阶段。
A.数据库系统 B.文件系统 C.人工管理 D.数据项管理
2.下面列出的数据库管理技术发展的三个阶段中,没有专门的软件对数据进行管理的是 。
Ⅰ.人工管理阶段 Ⅱ.文件系统阶段 Ⅲ.数据库阶段
A.Ⅰ和Ⅱ B.只有Ⅱ C.Ⅱ和Ⅲ D.只有Ⅰ
3.数据库的基本特点是 。
A.(1)数据可以共享 (2)数据独立性高
—4—
(3)数据冗余大,易移植 (4)统一管理和控制
B.(1)数据可以共享 (2)数据独立性高
(3)数据冗余小,易扩充 (4)统一管理和控制
C.(1)数据可以共享 (2)数据互换性
(3)数据冗余小,易扩充 (4)统一管理和控制
D.(1)数据非结构化 (2)数据独立性高
(3)数据冗余小,易扩充 (4)统一管理和控制
4. 是存储在计算机内有结构的数据的集合。
A.数据库系统 B.数据库
C.数据库管理系统 D.数据结构
5.数据库中存储的是 。
A.数据 B.数据模型
C.数据以及数据之间的联系 D.信息
6.数据库中,数据的物理独立性是指 。
A.数据库与数据库管理系统的相互独立
B.用户程序与DBMS的相互独立
C.用户的应用程序与存储在磁盘上数据库中的数据是相互独立的
D.应用程序与数据库中数据的逻辑结构相互独立
7.数据库的特点之一是数据的共享,严格地讲,这里的数据共享是指 。
A.同一个应用中的多个程序共享一个数据集合
B.多个用户、同一种语言共享数据
C.多个用户共享一个数据文件
D.多种应用、多种语言、多个用户相互覆盖地使用数据集合
8.据库系统的核心是 。
A.数据库 B.数据库管理系统
C.数据模型 D.软件工具
9.下述关于数据库系统的正确叙述是 。
A.数据库系统减少了数据冗余
B.数据库系统避免了一切冗余
C.数据库系统中数据的一致性是指数据类型一致
D.数据库系统比文件系统能管理更多的数据
10.数据库系统的特点是 、数据独立、减少数据冗余、避免数据不一致和加强了数据保
护。
A.数据共享 B.数据存储 C.数据应用 D.数据保密
11.据库系统的最大特点是 。
A.数据的三级抽象和二级独立性 B.数据共享性
—5—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
C.数据的结构化 D.数据独立性
12.数据库管理系统能实现对数据库中数据的查询、插入、修改和删除等操作,这种功能称为
。
A.数据定义功能 B.数据管理功能
C.数据操纵功能 D.数据控制功能
13.数据库管理系统是 。
A.操作系统的一部分
B.在操作系统支持下的系统软件
C.一种编译程序
D.一种操作系统
二、填空题
1.数据管理技术经历了 、 和 三个阶段。
2.数据库是长期存储在计算机内、有 的、可 的数据集合。
3.DBMS是指 ,它是位于 和 之间的一层管理软
件。
4.数据库管理系统的主要功能有 、 、数据库
的运行管理和数据库的建立以及维护等4个方面。
5.数据独立性又可分为 和 。
6.当数据的物理存储改变了,应用程序不变,而由 DBMS处理这种改变,这是指数据的
。
三、简答题
1.什么是数据库?
2.什么是数据库的数据独立性?
3.什么是数据字典?数据字典包含哪些基本内容?
第2讲 数据模型
第一部分 知识点回顾
数据模型
·在数据库中用数据模型这个工具来抽象、表示和处理现实世界中的数据和信息。
·通俗地讲数据模型就是现实世界的模拟。
·数据模型应满足三方面要求
能比较真实地模拟现实世界
容易为人所理解
—6—
便于在计算机上实现
1.2 数据模型
1.2.1 两大类数据模型
数据模型分为两类(分属两个不同的层次)
(1)概念模型,也称信息模型,它是按用户的观点来对数据和信息建模,用于数据库设计。
(2)逻辑模型和物理模型
·逻辑模型主要包括网状模型、层次模型、关系模型、面向对象模型等,按计算机系统的观点对数
据建模,用于DBMS实现。
·物理模型是对数据最底层的抽象,描述数据在系统内部的表示方式和存取方法,在磁盘或磁带
上的存储方式和存取方法。
1.2.2 数据模型的组成要素
·数据结构 (描述数据库的组成对象,以及对象之间的联系)
·数据操作 (对数据库中各种对象(型)的实例(值)允许执行的操作及有关的操作规则)
·完整性约束条件(给定的数据模型中数据及其联系所具有的制约和储存规则,用以限定符合数
据模型的数据库状态以及状态的变化,以保证数据的正确、有效、相容。)
1.2.3 概念模型
·信息世界中的基本概念
·两个实体型之间的联系
·两个以上实体型之间的联系
·单个实体型内的联系
·概念模型的一种表示方法
·一个实例
1、信息世界中的基本概念
(1)实体(Entity)
客观存在并可相互区别的事物称为实体。
可以是具体的人、事、物或抽象的概念。
(2)属性(Atribute)
实体所具有的某一特性称为属性。
一个实体可以由若干个属性来刻画。
(3)码(Key)
唯一标识实体的属性集称为码。
(4)域(Domain)
属性的取值范围称为该属性的域。
(5)实体型(EntityType)
—7—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
用实体名及其属性名集合来抽象和刻画同类实体称为实体型
(6)实体集(EntitySet)
同一类型实体的集合称为实体集
(7)联系(Relationship)
现实世界中事物内部以及事物之间的联系在信息世界中反映为实体内部的联系和实体之间的联
系。
实体内部的联系通常是指组成实体的各属性之间的联系
实体之间的联系通常是指不同实体集之间的联系
2、两个实体型之间的联系
用图形来表示两个实体型之间的这三类联系
3、两个以上实体型之间的联系
·两个以上实体型之间一对多联系
若实体集E1,E2,...,En存在联系,对于实体集Ej(j=1,2,...,i-1,i+1,...,n)中的给定实体,
最多只和Ei中的一个实体相联系,则我们说Ei与 E1,E2,...,Ei-1,Ei+1,...,En之间的联系是一对多
的。
·实例
课程、教师与参考书三个实体型,一门课程可以有若干个教师讲授,使用若干本参考书,每一个教
师只讲授一门课程,每一本参考书只供一门课程使用
4、单个实体型内的联系
·一对多联系
—8—
实例
职工实体型内部具有领导与被领导的联系,某一职工(干部)“领导”若干名职工,一个职工仅被
另外一个职工直接领导,这是一对多的联系
5、概念模型的一种表示方法
·实体-联系方法(E-R方法)
用E-R图来描述现实世界的概念模型
E-R方法也称为E-R模型
一个实例
1.2.4 最常用的数据模型
·非关系模型
层次模型(HierarchicalModel)
网状模型(NetworkModel)
·关系模型(RelationalModel)
·面向对象模型(ObjectOrientedModel)
·对象关系模型(ObjectRelationalModel)
1.2.5 层次模型
1.2.6 网状模型
—9—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
1.2.7 关系模型
1、关系数据模型的数据结构
·在用户观点下,关系模型中数据的逻辑结构是一张二维表,它由行和列组成。
学生登记表
学 号 姓 名 年 龄 性 别 系 名 年 级
2005004 王小明 19 女 社会学 2005
2005006 黄大鹏 20 男 商品学 2005
2005008 张文斌 18 女 法律 2005
… … … … … …
·关系(Relation)
一个关系对应通常说的一张表
·元组(Tuple)
表中的一行即为一个元组
·属性(Atribute)
表中的一列即为一个属性,给每一个属性起一个名称即属性名
·主码(Key)
表中的某个属性组,它可以唯一确定一个元组。
·域(Domain)
属性的取值范围。
·分量
元组中的一个属性值。
·关系模式
对关系的描述
关系名(属性1,属性2,…,属性n)
学生(学号,姓名,年龄,性别,系,年级)
·关系必须是规范化的,满足一定的规范条件
最基本的规范条件:关系的每一个分量必须是一个不可分的数据项,不允许表中还有表
图1.27中工资和扣除是可分的数据项 ,不符合关系模型要求
职工号 姓名 职 称
工 资 扣 除
基 本 津 贴 职务 房 租 水 电
实 发
86051 陈 平 讲 师 1305 1200 50 160 112 2283
图1.27一个工资表(表中有表)实例
表1.2 术语对比
关系术语 一般表格的术语
—01—
关系名 表名
关系模式 表头(表格的描述)
关系 (一张)二维表
元组 记录或行
属性 列
属性名 列名
属性值 列值
分量 一条记录中的一个列值
非规范关系 表中有表(大表中嵌有小表)
2、关系数据模型的操纵与完整性约束
·数据操作是集合操作,操作对象和操作结果都是关系,即若干元组的集合
查询
插入
删除
更新
·关系的完整性约束条件
实体完整性
参照完整性
用户定义的完整性
3、关系数据模型的存储结构
·实体及实体间的联系都用表来表示
·表以文件形式存储
有的DBMS一个表对应一个操作系统文件
有的DBMS自己设计文件结构
4、关系数据模型的优缺点
·优点
建立在严格的数学概念的基础上
概念单一
实体和各类联系都用关系来表示
对数据的检索结果也是关系
关系模型的存取路径对用户透明
具有更高的数据独立性,更好的安全保密性
—11—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
简化了程序员的工作和数据库开发建立的工作
·缺点
存取路径对用户透明导致查询效率往往不如非关系数据模型
为提高性能,必须对用户的查询请求进行优化,增加了开发DBMS的难度
第二部分 考点试题解析
一、选择题
1.信息世界中的术语,与之对应的数据库术语为 。
A.文件 B.数据库 C.字段 D.记录
2.层次型、网状型和关系型数据库划分原则是 。
A.记录长度 B.文件的大小
C.联系的复杂程度 D.数据之间的联系
3.传统的数据模型分类,数据库系统可以分为三种类型 。
A.大型、中型和小型 B.西文、中文和兼容
C.层次、网状和关系 D.数据、图形和多媒体
4.层次模型不能直接表示 。
A.1:1关系 B.1:m关系
C.m:n关系 D.1:1和1:m关系
5.数据库技术的奠基人之一E.F.Codd从1970年起发表过多篇论文,主要论述的是 。
A.层次数据模型 B.网状数据模型
C.关系数据模型 D.面向对象数据模型
6.在数据库中,产生数据不一致的根本原因是 。
A.数据存储量太大 B.没有严格保护数据
C.未对数据进行完整性控制 D.数据冗余
7.数据库的概念模型独立于 。
A.具体的机器和DBMS B.E-R图
C.信息世界 D.现实世界
8.描述数据库全体数据的全局逻辑结构和特性的是 。
A.模式 B.内模式 C.外模式 D.用户模式
9.要保证数据库的数据独立性,需要修改的是 。
A.模式与外模式 B.模式与内模式
C.三层之间的两种映射 D.三层模式
10.用户或应用程序看到的那部分局部逻辑结构和特征的描述是 ,它是模式的逻辑子集。
A.模式 B.物理模式 C.子模式 D.内模式
二、填空题
1.数据模型是由 、 和 三部分组成的。
—21—
2. 是对数据系统的静态特性的描述, 是对数据库系
统的动态特性的描述。
3.数据库体系结构按照 、 和 三级结构
进行组织。
4.实体之间的联系可抽象为三类,它们是 、 和 。
5.数据冗余可能导致的问题有 和 。
三、简答题
1.使用数据库系统有什么好处?
2.试述文件系统与数据库系统的区别和联系。
3.试述数据库系统的特点。
4.试述数据模型的概念、数据模型的作用和数据模型的三个要素。
5.试述概念模型的作用。
6.试给出三个实际部门的E-R图,要求实体型之间具有一对一,一对多,多对多各种不同的联
系。
第3讲 数据库系统结构及组成
第一部分 知识点回顾
·从数据库管理系统角度看,数据库系统通常采用三级模式结构,是数据库系统内部的系统结构
·从数据库最终用户角度看(数据库系统外部的体系结构),数据库系统的结构分为:
单用户结构
主从式结构
分布式结构
客户/服务器
浏览器/应用服务器/数据库服务器多层结构等
1.3 数据库系统结构
1.3.1 数据库系统模式的概念
·“型”和“值”的概念
型(Type):对某一类数据的结构和属性的说明
值(Value):是型的一个具体赋值
例如:
学生记录型:(学号,姓名,性别,系别,年龄,籍贯)
一个记录值:(900201,李明,男,计算机,22,江苏)
·模式(Schema)
—31—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
数据库逻辑结构和特征的描述
是型的描述
反映的是数据的结构及其联系
模式是相对稳定的
·实例(Instance)
模式的一个具体值
反映数据库某一时刻的状态
同一个模式可以有很多实例
实例随数据库中的数据的更新而变动
1.3.2 数据库系统的三级模式结构
图1.28 数据库系统的三级模式结构
1、模式(Schema)
·模式(也称逻辑模式)
数据库中全体数据的逻辑结构和特征的描述
所有用户的公共数据视图,综合了所有用户的需求
·一个数据库只有一个模式
·模式的地位:是数据库系统模式结构的中间层
与数据的物理存储细节和硬件环境无关
与具体的应用程序、开发工具及高级程序设计语言无关
·模式的定义
数据的逻辑结构(数据项的名字、类型、取值范围等)
数据之间的联系
数据有关的安全性、完整性要求
—41—
2、外模式(ExternalSchema)
·外模式(也称子模式或用户模式)
数据库用户(包括应用程序员和最终用户)使用的局部数据的逻辑结构和特征的描述
数据库用户的数据视图,是与某一应用有关的数据的逻辑表示
·外模式的地位:介于模式与应用之间
模式与外模式的关系:一对多
外模式通常是模式的子集
一个数据库可以有多个外模式。反映了不同的用户的应用需求、看待数据的方式、对数据保密
的要求
对模式中同一数据,在外模式中的结构、类型、长度、保密级别等都可以不同
·外模式与应用的关系:一对多
同一外模式也可以为某一用户的多个应用系统所使用
但一个应用程序只能使用一个外模式
·外模式的用途
保证数据库安全性的一个有力措施
每个用户只能看见和访问所对应的外模式中的数据
3、内模式(InternalSchema)
·内模式(也称存储模式)
是数据物理结构和存储方式的描述
是数据在数据库内部的表示方式
记录的存储方式(顺序存储,按照B树结构存储,按hash方法存储)
索引的组织方式
数据是否压缩存储
数据是否加密
数据存储记录结构的规定
·一个数据库只有一个内模式
例如:学生记录,如果按堆存储,则插入一条新记录总是放在学生记录存储的最后,如下图所
示:
·如果按学号升序存储,则插入一条记录就要找到它应在的位置插入。如图(b)所示
·如果按照学生年龄聚簇存放,假如新插入的S3是16岁,则应插入的位置。如图(c)所示
—51—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
1.3.3 数据库的二级映像功能与数据独立性
·三级模式是对数据的三个抽象级别
·二级映象在DBMS内部实现这三个抽象层次的联系和转换
外模式/模式映像
模式/内模式映像
1、外模式/模式映象
·模式:描述的是数据的全局逻辑结构
·外模式:描述的是数据的局部逻辑结构
·同一个模式可以有任意多个外模式
·每一个外模式,数据库系统都有一个外模式/模式映象,定义外模式与模式之间的对应关系
·映象定义通常包含在各自外模式的描述中
保证数据的逻辑独立性
·当模式改变时,数据库管理员修改有关的外模式/模式映象,使外模式保持不变
·应用程序是依据数据的外模式编写的,从而应用程序不必修改,保证了数据与程序的逻辑独立
性,简称数据的逻辑独立性。
2、模式/内模式映像
·模式/内模式映象定义了数据全局逻辑结构与存储结构之间的对应关系。
例如,说明逻辑记录和字段在内部是如何表示的
·数据库中模式/内模式映象是唯一的
·该映象定义通常包含在模式描述中
保证数据的物理独立性
—61—
·当数据库的存储结构改变了(例如选用了另一种存储结构),数据库管理员修改模式/内模式映
象,使模式保持不变
·应用程序不受影响。保证了数据与程序的物理独立性,简称数据的物理独立性。
图1.28 数据库系统的三级模式结构
1.4 数据库系统的组成
·数据库
·数据库管理系统(及其开发工具)
·应用系统
·数据库管理员
·硬件平台及数据库
·软件
·人员
1.4.1数据库管理员(DBA)
具体职责:
(1)决定数据库中的信息内容和结构
(2)决定数据库的存储结构和存取策略
(3)定义数据的安全性要求和完整性约束条件
(4)监控数据库的使用和运行
·周期性转储数据库(数据文件,日志文件)
·系统故障恢复;介质故障 恢复
·监视审计文件
(5)数据库的改进和重组
·性能监控和调优
—71—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·定期对数据库进行重组织,以提高系统的性能
·需求增加和改变时,数据库须需要重构造
1.4.2系统分析员和数据库设计人员
·系统分析员
负责应用系统的需求分析和规范说明
与用户及DBA协商,确定系统的硬软件配置
参与数据库系统的概要设计
·数据库设计人员
参加用户需求调查和系统分析
确定数据库中的数据
设计数据库各级模式
1.4.3应用程序员及用户
·应用程序员
设计和编写应用系统的程序模块
进行调试和安装
·用户
用户是指最终用户(EndUser)。最终用户通过应用系统的用户接口使用数据库。
(1)偶然用户:不经常访问数据库,但每次访问数据库时往往需要不同的数据库信息 ,例如企业
或组织机构的高中级管理人员;
(2)简单用户:主要工作是查询和更新数据库 ,例如银行的职员、机票预定人员、旅馆总台服务
员;
(3)复杂用户:直接使用数据库语言访问数据库,甚至能够基于数据库管理系统的 API编制自己
的应用程序,例如工程师、科学家、经济学家、科技工作者等。
1.5 小结
·数据库系统概述
数据库的基本概念
数据管理的发展过程
·数据模型
数据模型的三要素
概念模型,E-R模型
三种主要数据库模型
·数据库系统的结构
数据库系统三级模式结构
数据库系统两层映像系统结构
·数据库系统的组成
—81—
第二部分 考点例题解析
一、选择题
1.下述 不是DBA数据库管理员的职责 。
A.完整性约束说明 B.定义数据库模式
C.数据库安全 D.数据库管理系统设计
2.数据库(DB),数据库系统(DBS)和数据库管理系统(DBMS)之间的关系是 。
A.DBS包括DB和DBMS B.DBMS包括DB和DBS
C.DB包括DBS和DBMS D.DBS就是DB,也就是DBMS
3.DBS是采用了数据库技术的计算机系统,它是一个集合体,包含数据库、计算机硬件、软件和
。
A.系统分析员 B.程序员
C.数据库管理员 D.操作员
4.数将数据库的结构划分成多个层次,是为了提高数据库的 ① 和 ② 。
①A.数据独立性 B.逻辑独立性
C.管理规范性 D.数据的共享
②A.数据独立性 B.物理独立性
C.逻辑独立性 D.管理规范性
5.数据库的三级模式结构中,描述数据库中全体数据的全局逻辑结构和特征的是 。
A.外模式 B.内模式 C.存储模式 D.模式
6.数据库系统的数据独立性是指 。
A.不会因为数据的变化而影响应用程序
B.不会因为系统数据存储结构与数据逻辑结构的变化而影响应用程序
C.不会因为存储策略的变化而影响存储结构
D.不会因为某些存储结构的变化而影响其他的存储结构
二、填空题
1.数据库管理系统是数据库系统的一个重要组成部分,它的功能包括 : 、 、数
据组织存储和管理、数据库运行管理和事物管理、数据库的建立和维护功能。
2.数据库系统是指在计算机系统中引入数据库后的系统,一般由数据库、 、
和数据库管理员构成。
3. 模型是目前最常用也是最重要的一种数据模型。采用该模型作为数据的组织方
式的数据库系统称为 。
4.数据冗余可能导致的问题有 和 。
三、简答题
1.数据库管理系统的主要功能有哪些?
2.什么是数据库管理系统?
—91—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
第二章 关系数据库
第1讲 关系模型三要素
第一部分 知识点回顾
2.1 关系数据结构及形式化定义
2.1.1 关系
(1)域:域是一组具有相同数据类型的值的集合。
(2)笛卡尔积:给定一组域D1,D2,…,Dn,这些域中可以有相同的。
D1,D2,…,Dn的笛卡尔积为:
D1×D2×… ×Dn ={(d1,d2,…,dn)|di Di,i=1,2,…,n}
所有域的所有取值的一个组合
不能重复
元组(Tuple)
·笛卡尔积中每一个元素(d1,d2,…,dn)叫作一个n元组(n-tuple)或简称元组(Tuple)
·(张清玫,计算机专业,李勇)、(张清玫,计算机专业,刘晨)等都是元组
分量(Component)
·笛卡尔积元素(d1,d2,…,dn)中的每一个值 di叫作一个分量
·张清玫、计算机专业、李勇等都是分量
基数(Cardinalnumber)
·若Di(i=1,2,…,n)为有限集,其基数为mi(i=1,2,…,n),则D1×D2×…×Dn的基数M为:
M =Π
n
i=1
mi
笛卡尔积的表示方法
·笛卡尔积可表示为一个二维表
·表中的每行对应一个元组,表中的每列对应一个域
表2.1 D1,D2,D3的笛卡尔积
SUPE RVISOR SPECIALITY POSTGRADUATE
张清玫 计算机专业 李 勇
张清玫 计算机专业 刘 晨
张清玫 计算机专业 王 敏
—02—
续表
SUPE RVISOR SPECIALITY POSTGRADUATE
张清玫 信息专业 李 勇
张清玫 信息专业 刘 晨
张清玫 信息专业 王 敏
刘 逸 计算机专业 李 男
刘 逸 计算机专业 刘 晨
刘 逸 计算机专业 王 敏
刘 逸 信息专业 李 男
刘 逸 信息专业 刘 晨
刘 逸 信息专业 王 敏
3.关系(Relation)
1)关系
D1×D2×… ×Dn的子集叫作在域D1,D2,…,Dn上的关系,表示为:
R(D1,D2,…,Dn),
其中:
R:关系名
n:关系的目或度(Degree)
2)元组
关系中的每个元素是关系中的元组,通常用 t表示。
3)单元关系与二元关系
当n=1时,称该关系为单元关系,或一元关系
当n=2时,称该关系为二元关系
4)关系的表示
关系也是一个二维表,表的每行对应一个元组,表的每列对应一个域
5)属性
关系中不同列可以对应相同的域
为了加以区分,必须对每列起一个名字,称为属性
n目关系必有n个属性
6)码
·候选码(Candidatekey)
若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码
·全码(Al-key)
最极端的情况:关系模式的所有属性组是这个关系模式的候选码,称为全码(Al-key)
·主码
—12—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
若一个关系有多个候选码,则选定其中一个为主码(Primarykey)
·主属性
候选码的诸属性称为主属性(Primeatribute)
不包含在任何侯选码中的属性称为非主属性,或非码属性
7)三类关系
·基本关系(基本表或基表):实际存在的表,是实际存储数据的逻辑表示
·查询表:查询结果对应的表
·视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据
8)基本关系的性质
① 列是同质的(Homogeneous)
② 不同的列可出自同一个域
·其中的每一列称为一个属性
·不同的属性要给予不同的属性名
③ 列的顺序无所谓,,列的次序可以任意交换
④ 任意两个元组的候选码不能相同
⑤ 行的顺序无所谓,行的次序可以任意交换
⑥ 分量必须取原子值
这是规范条件中最基本的一条
表2.3 非规范化关系
2.1.2 关系模式
1.什么是关系模式
·关系模式(RelationSchema)是型
·关系是值
·关系模式是对关系的描述
·元组集合的结构
属性构成
属性来自的域
属性与域之间的映象关系
·元组语义以及完整性约束条件
·属性间的数据依赖关系集合
—22—
考试点(www.kaoshidian.com)名师精品课程 电话:4006885365
2.定义关系模式
关系模式可以形式化地表示为:
R(U,D,DOM,F)
R:关系名
U:组成该关系的属性名集合
D:属性组U中属性所来自的域
DOM:属性向域的映象集合
F:属性间的数据依赖关系集合
关系模式通常可以简记为
R(U) 或 R(A1,A2,…,An)
R:关系名
A1,A2,…,An:属性名
注:域名及属性向域的映象常常直接说明为属性的类型、长度
3.关系模式与关系
·关系模式
对关系的描述
静态的、稳定的
·关系
关系模式在某一时刻的状态或内容
动态的、随时间不断变化的
·关系模式和关系往往统称为关系
通过上下文加以区别
2.1.3 关系数据库
1.关系数据库
·在一个给定的应用领域中,所有关系的集合构成一个关系数据库
2.关系数据库的型与值
·关系数据库的型:关系数据库模式
对关系数据库的描述。
·关系数据库模式包括
若干域的定义
在这些域上定义的若干关系模式
·关系数据库的值:关系模式在某一时刻对应的关系的集合,简称为关系数据库
—32—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
2.2 关系操作
2.2.1 基本关系操作
·常用的关系操作
查询:选择、投影、连接、除、并、交、差
数据更新:插入、删除、修改
查询的表达能力是其中最主要的部分
选择、投影、并、差、笛卡尔基是5种基本操作
·关系操作的特点
集合操作方式:操作的对象和结果都是集合,一次一集合的方式
2.2.2 关系数据库语言的分类
·关系代数语言
用对关系的运算来表达查询要求
代表:ISBL
·关系演算语言:用谓词来表达查询要求
元组关系演算语言
谓词变元的基本对象是元组变量
代表:APLHA,QUEL
域关系演算语言
谓词变元的基本对象是域变量
代表:QBE
·具有关系代数和关系演算双重特点的语言
代表:SQL(StructuredQueryLanguage)
2.3 关系的完整性
2.3.1 关系的三类完整性约束
·实体完整性和参照完整性:
关系模型必须满足的完整性约束条件
称为关系的两个不变性,应该由关系系统自动支持
·用户定义的完整性:
应用领域需要遵循的约束条件,体现了具体领域中的语义约束
2.3.2 实体完整性
·规则2.1 实体完整性规则(EntityIntegrity)
若属性A是基本关系R的主属性,则属性A不能取空值
例:
SAP(SUPERVISOR,SPECIALITY,POSTGRADUATE)
—42—
考试点(www.kaoshidian.com)名师精品课程 电话:4006885365
POSTGRADUATE:
主码(假设研究生不会重名)
不能取空值
注意:
实体完整性规则规定基本关系的所有主属性都不能取空值,而不仅是主码整体不能取空值。
【例】
选修(学号,课程号,成绩)
“学号、课程号”为主码,则学号和课程号两个属性都不能取空值
2.3.3 参照完整性
1.关系间的引用
·在关系模型中实体及实体间的联系都是用关系来描述的,因此可能存在着关系与关系间的引
用。
例1:学生实体、专业实体
学生(学号,姓名,性别,专业号,年龄)
专业(专业号,专业名)
·学生关系引用了专业关系的主码“专业号”。
·学生关系中的“专业号”值必须是确实存在的专业的专业号 ,即专业 关系中有该专业的记录。
2.外码(ForeignKey)
·设F是基本关系R的一个或一组属性,但不是关系R的码。如果F与基本关系S的主码Ks相
对应,则称F是基本关系R的外码
·基本关系R称为参照关系(ReferencingRelation)
·基本关系S称为被参照关系(ReferencedRelation)或目标关系(TargetRelation)
【例】 学生关系的“专业号与专业关系的主码“专业号”相对应。
·“专业号”属性是学生关系的外码
·专业关系是被参照关系,学生关系为参照关系
学生关系
专业号
(n→
)
专业关系
·关系 R和 S不一定是不同的关系
·目标关系 S的主码 Ks和参照关系的外码F必须定义在同一个(或一组)域上
·外码并不一定要与相应的主码同名
当外码与相应的主码属于不同关系时,往往取相同的名字,以便于识别
3.参照完整性规则
·规则2.2参照完整性规则
若属性(或属性组)F是基本关系R的外码它与基本关系S的主码Ks相对应(基本关系R和S不
一定是不同的关系),则对于R中每个元组在F上的值必须为:
—52—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·或者取空值(F的每个属性值均为空值)
·或者等于S中某个元组的主码值
【例】 学生关系中每个元组的“专业号”属性只取两类值:
(1)空值,表示尚未给该学生分配专业;
(2)非空值,这时该值必须是专业关系中某个元组的“专业号”值,表示该学生不可能分配一 不
存在的专业。
2.3.4 用户定义的完整性
·针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求。
·关系模型应提供定义和检验这类完整性的机制,以便用统一的系统的方法处理它们,而不要由
应用程序承担这一功能。
【例】 课程(课程号,课程名,学分)
·“课程号”属性必须取唯一值
·非主属性“课程名”也不能取空值
·“学分”属性只能取值{1,2,3,4}
第二部分 考点试题解析
一、选择题
1.关系模型中,一个关键字是 。
A.可由多个任意属性组成
B.至多由一个属性组成
C.可由一个或多个其值能惟一标识该关系模式中任何元组的属性组成
D.以上都不是
2.关系模式的任何属性 。
A.不可再分 B.可再分
C.命名在该关系模式中可以不惟一 D.以上都不是
3.下面的选项不是关系数据库基本特征的是 。
A.不同的列应有不同的数据类型
B.不同的列应有不同的列名
C.与行的次序无关
D.与列的次序无关
4.一个关系只有一个 。
A.候选码 B.外码 C.超码 D.主码
5.关系DBS中,对外部关键字(外码)没有任何限制的操作是 。
A.插入 B.删除 C.修改
6.现有如下关系:
患者(患者编号,患者姓名,性别,出生日起,所在单位)
—62—
医疗(患者编号,患者姓名,医生编号,医生姓名,诊断日期,诊断结果)
其中,医疗关系中的外码是 。
A.患者编号 B.患者姓名
C.患者编号和患者姓名 D.医生编号和患者编号
7.现有一个关系:借阅(书号,书名,库存数,读者号,借期,还期),假如同一本书允许一个读者多
次借阅,但不能同时对一种书借多本,则该关系模式的主码是 。
A.书号 B.读者号
C.书号+读者号 D.书号+读者号+借期
8.关系模型中实现实体间 N:M联系是通过增加一个 。
A.关系实现 B.属性实现
C.关系或一个属性实现 D.关系和一个属性实现
二、填空题
1.一个关系模式的定义格式为 。
2.一个关系模式的定义主要包括 、 、 、 和
。
3.关系数据库中基于数学上两类运算是 和 。
4.已知系(系编号,系名称,系主任,电话,地点)和学生(学号,姓名,性别,入学日期,专业,系编
号)两个关系,系关系的主关键字是 ,系关系的外关键字 ,学生
关系的主关键字是 ,外关键字 。
三、简答题
1.试述关系模型的三个组成部分。
2.试述关系数据语言的特点和分类。
3.试述关系模型的完整性规则。在参照完整性中,为什么外部码属性的值也可以为空?什么情
况下才可以为空?
第2讲 关系代数及关系演算
第一部分 知识点回顾
2.4 关系代数
·概述(集合运算符,比较运算符,专门关系运算符,逻辑运算符)
·传统的集合运算
·专门的关系运算
2.4.1 关系代数运算符
·集合运算符: ∪, ∩ , -, ×
—72—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·关系运算符: <, < =, =, < >, >, > =
·专门关系运算符: σ, ∏, ∞, ÷
·逻辑运算符: Λ, V, ˉ
2.4.2 传统的集合运算
R∪S={t|t∈R∨t∈S}
R-S={t|t∈R∧tS}
R∩S={t|t∈R∧t∈S}
R∩S=R-(R-S)
R×S={trt
)
s|tr∈R∧ts∈S}
2.4.3 专门的关系运算
先引入几个记号
(1)R,t∈R,t[Ai]
(2)A,t[A],A
(3)trt
)
s
(4)象集Zx ={t[Z]|t∈R,t[X]=x}
专门关系运算符含义
1.σF(R)={t|t∈R∧F(t)=‘真’}
F:选择条件,是一个逻辑表达式,基本形式为:X1θY1
2.πA(R)={tA|t∈R}
A:R中的属性列
3.R
!
R,AθS,B
S={trt
)
s|tr∈R∧ts∈S∧tr Aθts B}
【例1】关系R和关系S如下所示:
—82—
一般连接R
C<E
S的结果如下:
等值连接R
R,B=S,B
S的结果如下:
—92—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
自然连接RS的结果如下:
·外连接
如果把舍弃的元组也保存在结果关系中,而在其他属性上填空值(Nul),这种连接就叫做外连
接(OUTERJOIN)。
·左外连接
如果只把左边关系R中要舍弃的元组保留就叫做左外连接(LEFTOUTERJOIN或LEFTJOIN)
·右外连接
如果只把右边关系 S中要舍弃的元组保留就叫做右外连接(RIGHTOUTERJOIN或 RIGHT
JOIN)
下图是【例1】中关系R和关系S的外连接
图(b)是【例1】中关系R和关系S的左外连接,图(c)是右外连接
4.除(Division)
给定关系R(X,Y)和S(Y,Z),其中X,Y,Z为属性组。
R÷S={tr X|tr∈R∧πY(S)YX}
—03—
YX:X在R中的象集,X=tr|X|
【例2】设关系R、S分别为下图的(a)和(b),R÷S的结果为图(c)
分析:
·在关系R中,A可以取四个值{a1,a2,a3,a4}
a1的象集为 {(b1,c2),(b2,c3),(b2,c1)}
a2的象集为 {(b3,c7),(b2,c3)}
a3的象集为 {(b4,c6)}
a4的象集为 {(b6,c6)}
·S在(B,C)上的投影为{(b1,c2),(b2,c1),(b2,c3)}
·只有a1的象集包含了S在(B,C)属性组上的投影,所以R÷S={a1}
【例3】查询选修了全部课程的学生号码和姓名。
ΠSno,Cno(SC)÷ΠCno(Course)ΠSno,Sname(Student)
2.4.4 小结
·关系代数运算
并、差、交、笛卡尔积、投影、选择、连接、除
·基本运算
并、差、笛卡尔积、投影、选择
·交、连接、除
可以用5种基本运算来表达
引进它们并不增加语言的能力,但可以简化表达
·关系代数表达式
关系代数运算经有限次复合后形成的式子
·典型关系代数语言
ISBL(InformationSystemBaseLanguage)
·由IBMUnitedKingdom研究中心研制
·用于PRTV(PeterleeRelationalTestVehicle)实验系统
—13—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
2.5 关系演算
·关系演算
以数理逻辑中的谓词演算为基础
·按谓词变元不同进行分类
1.元组关系演算:
以元组变量作为谓词变元的基本对象
元组关系演算语言ALPHA
2.域关系演算:
以域变量作为谓词变元的基本对象
域关系演算语言QBE
2.6 小结
·关系数据库系统是目前使用最广泛的数据库系统
·关系数据库系统与非关系数据库系统的区别:
·关系数据结构
·关系操作
·关系的完整性约束
·关系数据语言
第二部分 考点试题解析
一、选择题
1.自然连接是构成新关系的有效方法。一般情况下,当对关系R和S使用自然连接时,要求R和
S含有一个或多个共有的 。
A.元组 B.行 C.记录 D.属性
2.关系运算中花费时间可能最长的运算是 。
A.投影 B.选择 C.笛卡尔积 D.除
3.在关系代数运算中,五种基本运算为 。
A.并、差、选择、投影、自然连接
B.并、差、交、选择、投影
C.并、差、选择、投影、乘积
D.并、差、交、选择、乘积
4.设有关系R,按条件f对关系R进行选择,正确的是 。
A.R×R B.R
F
R C.σF(R) D.πF(R)
5.如图所示,两个关系R1和R2,它们进行 运算后得到R3。
—23—
A.交 B.并 C.笛卡尔积 D.连接
6.关系代数运算是以 为基础的运算 。
A.关系运算 B.谓词演算
C.集合运算 D.代数运算
7.关系数据库管理系统应能实现的专门关系运算包括 。
A.排序、索引、统计 B.选择、投影、连接
C.关联、更新、排序 D.显示、打印、制表
8.关系代数表达式的优化策略中,首先要做的是 。
A.对文件进行预处理 B.尽早执行选择运算
C.执行笛卡尔积运算 D.投影运算
9.关系数据库中的投影操作是指从关系中 。
A.抽出特定记录 B.抽出特定字段
C.建立相应的影像 D.建立相应的图形
10.从一个数据库文件中取出满足某个条件的所有记录形成一个新的数据库文件的操作是
操作 。
A.投影 B.联接 C.选择 D.复制
11.关系代数中的联接操作是由 操作组合而成 。
A.选择和投影 B.选择和笛卡尔积
C.投影、选择、笛卡尔积 D.投影和笛卡尔积
12.自然联接是构成新关系的有效方法。一般情况下,当对关系 R和 S是用自然联接时,要求 R
和S含有一个或者多个共有的 。
A.记录 B.行 C.属性 D.元组
13.假设有关系 R和 S,关系代数表达式 R-(R-S)表示的是 。
A.R∩S B.R∪S C.R-S D.R×S
14.下面列出的关系代数表达式中,那些式子能够成立 。
Ⅰ.σf1(σf2(E))=σf1∧f2(E)
Ⅱ.E1∞E2=E2∞E1
Ⅲ.(E1∞E2)∞E3=E1∞ (E2∞E3)
Ⅳ.σf1(σf2(E))=σf2(σf1(E))
A.全部 B.Ⅱ和Ⅲ C.没有 D.Ⅰ和Ⅳ
二、填空题
1.关系代数运算中,传统的集合运算有 、 、 和 。
2.关系代数运算中,基本的运算是 、 、 、和 。
3.关系代数运算中,专门的关系运算有 、 、 和
。
—33—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
若对于R(U)的任意一个可能的关系 r,r中不可能存在两个元组在 X上的属性值相等,而在 Y
上的属性值不等,则称 “X函数确定Y”或“Y函数依赖于X”,记作X→Y。
2、平凡函数依赖与非平凡函数依赖
在关系模式R(U)中,对于U的子集X和Y,
如果X→Y,但YX,则称X→Y是 非平凡的函数依赖
若X→Y,但YX,则称X→Y是平凡的函数依赖
例:在关系SC(Sno,Cno,Grade)中,
非平凡函数依赖:(Sno,Cno)→ Grade
平凡函数依赖:(Sno,Cno)→ Sno
(Sno,Cno)→ Cno
·若X→Y,则X称为这个函数依赖的决定属性组,也称为决定因素(Determinant)。
·若X→Y,Y→X,则记作X←→Y。
·若Y不函数依赖于X,则记作X→Y。
3、完全函数依赖与部分函数依赖
定义6.2 在R(U)中,如果X→Y,并且对于X的任何一个真子集X',都有X'→/Y,则称Y对X完
全函数依赖,记作X →
F
Y。
若X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖,记作X →
P
Y。
例如 :(Sno,Cno)→ grade(完全函数依赖)
(Sno,Cno)→sdept(部分函数依赖)
4、传递函数依赖
定义6.3 在R(U)中,如果X→Y,(YX),Y→/XY→Z,则称Z对X传递函数依赖。
记为:X →
传递
Z
注:如果Y→X,即X←→Y,则Z直接依赖于X。
例:在关系Std(Sno,Sdept,Mname)中,有:
Sno→ Sdept,Sdept→ Mname
Mname传递函数依赖于Sno
6.2.2 码
定义6.4 设K为R<U,F>中的属性或属性组合。若 K →
F
C,则 K称为 R的侯选码(Candi
dateKey)。
若候选码多于一个,则选定其中的一个做为主码(PrimaryKey)。
·主属性与非主属性
包含在任何一个候选码中的属性 ,称为主属性(Primeatribute)
不包含在任何码中的属性称为非主属性(Nonprimeatribute)或非码属性(Non-keyatribute)
—08—
·全码
整个属性组是码,称为全码(Al-key)
外部码
定义6.5 关系模式 R中属性或属性组X并非 R的码,但 X是另一个关系模式的码,则称 X是
R的外部码(Foreignkey)也称外码。
·如在SC(Sno,Cno,Grade)中,Sno不是码,但Sno是关系模式S(Sno,Sdept,Sage)的码,则Sno是
关系模式SC的外部码
·主码与外部码一起提供了表示关系间联系的手段
6.2.3 范式
·范式是符合某一种级别的关系模式的集合
·关系数据库中的关系必须满足一定的要求。满足不同程度要求的为不同范式
·范式的种类:
第一范式(1NF)
第二范式(2NF)
第三范式(3NF)
BC范式(BCNF)
第四范式(4NF)
第五范式(5NF
)
·各种范式之间存在联系:
1NF2NF3NFBCNF4NF5NF
·某一关系模式R为第n范式,可简记为R∈nNF。
·一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式的集合,
这种过程就叫规范化。
6.2.4 2NF
·1NF的定义
如果一个关系模式R的所有属性都是不可分的基本数据项,则R∈1NF。
第一范式是对关系模式的最起码的要求。不满足第一范式的数据库模式不能称为关系数据库。
但是满足第一范式的关系模式并不一定是一个好的关系模式。
·2NF的定义
定义6.6 若R∈1NF,且每一个非主属性完全函数依赖于码,则R∈2NF。
例:S-L-C(Sno,Sdept,Sloc,Cno,Grade)∈1NF
S-L-C(Sno,Sdept,Sloc,Cno,Grade)∈2NF
SC(Sno,Cno,Grade)∈ 2NF
S-L(Sno,Sdept,Sloc)∈ 2NF
6.2.5 3NF
·3NF的定义
—18—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
定义6.7 关系模式R<U,F>中若不存在这样的码X、属性组Y及非主属性Z(ZY),使得
X→Y,Y→Z成立,Y/→X,则称R<U,F>∈ 3NF。
若R∈3NF,则每一个非主属性既不部分依赖于码也不传递依赖于码。
6.2.6 BC范式(BCNF)
定义6.8 关系模式R<U,F>∈1NF,若X→Y且YX时X必含有码,则R<U,F>∈BCNF。
等价于:每一个决定属性因素都包含码。
注:当X含有码时,X被称为超键。
·若R∈BCNF
所有非主属性对每一个码都是完全函数依赖
所有的主属性对每一个不包含它的码,也是完全函数依赖
没有任何属性完全函数依赖于非码的任何一组属性
·如果R∈3NF,且R只有一个候选码
第二部分 考点试题分析
一、判断题【2002重庆大学】
1.设有关系模式R(ABCDEF),F={AB CF,E AB,C D,D BF},问AB是R的候选码吗?
2.采用E-R数据模型方法对某一应用数据库系统进行需求分析和建立数据模型时,建立的数据
模型与将来采用的何种数据管理软件(DBMS)有关吗?
3.设有关系模式R(ABCDE),F={C DE},问R为3NF吗?
4.问下述SQL语句语法正确吗(其中temp和sp均为表格)?
insertintotemp(pno)asselectpnofromsp
5.一个关系的外键可由多个属性构成吗?
二、选择题
1.只有两个属性的关系,其最高范式必属于( )?【2002重大】
A.1NF B.2NF C.3NF D.4NF
2.关系数据模型是当前最常用的一种数据模型,它是用(①)结构来表示实体类型及实体之间的
联系的。关系数据库的数据操作语言(DML)主要包括(②)两类操作,关系模型的关系运算是以关系
代数为理论基础的,关系代数的基本操作是(③ )。【2004北师大】
—28—
① A.树 B.图 C.网络 D.二维表
②A.删除和插入 B.查询和检索
C.统计和修改 D.检索和更新
③A.并、差、笛卡尔积、投影、联接
B.并、差、笛卡尔积、选择、联接
C.并、差、笛卡尔积、投影、选择
D.并、差、笛卡尔积、除法、投影
3.设R和S为两个关系,则R|X|S表示R与S的(①)。若R和S的关系分别图示如下:
则R与S自然联接的结果是:(② )
供选择的答案:
① A.笛卡尔积 B.联接 C.Q联接 D.自然连接
②
3.设有一图书管理数据库,其关系模式是R0(L#,B#,BNAME,BPRICE,BPUB),其属性分别表示
个人借书证号、书号、书名、书价、图书出版社,则该关系模式(①)。他的主要问题是数据冗余。若把
—38—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
R0分解成两个关系模式R1(②)和R2(③),则可以部分的解决这一问题。R1和R2是规范化程度较
差的范式(④)。另一种分解方法可得到3个分解模式R3(L#,B#),R4(B#,BNAME),R5(BNAME,
BPRICE,BPUB),则R3,R4,R5都(⑤)。
供选择的答案:
①④⑤
A.属于第一范式,但不是第二范式
B.属于第二范式,但不是第三范式
C.属于第三范式
D.不是范式
E.属于第二范式,但不属于第一范式
F.属于第三范式,但不属于第二范式
②③
A.(L#,B#,BPRICE) B.(L#,B#)
C.(B#,BNAME) D.(B#,BNAME,BPRICE,BPUB)
E.(BNAME,BPRICE,BPUB) F.(L#,BNAME,BPRICE)
4.我们在一个关系中( )。【2012青岛大学】
A.必须定义一个主关键字
B.只能创建一个聚集索引(clusterindex)
C.只能创建一个稠密索引
D.只能定义一个约束
5.在DBMS的关系中( )。
A.关键字属性值可以为空 B.外关键字属性值可以为空
C.任何属性值都可以为空 D.任何属性值都不可以为空
6.设有关系模式R(B,I,S,Q,D),其上函数依赖集F={S D,I B,IS Q,B Q,B I},下面哪
个是R的关键字( )。
A.IS B.IB C.IQ D.ISB
7.关于第三范式描述正确的是( )。
A.一个关系属于第一范式,它就属于第三范式
B.一个关系模式属于BC范式,它就属于第三范式
C.一个关系实例有数据冗余,它就属于第三范式
D.一个关系实例没有数据冗余,它就属于第三范式
8.关系数据模型是目前最重要的一种数据模型,它的三个要素分别是( )。
A.实体完整性、参照完整性、用户自定义完整性
B.数据结构、关系操作、完整性约束
C.数据增加、数据修改、数据查询
D.外模式、模式、内模式
—48—
9.关于分布式数据库系统和并行数据库系统,下列说法正确的是( )。
A.分布式数据库系统的目标是利用多处理机结点并行地完成数据库任务以提高数据库系统的
整体性能
B.并行数据库系统目的主要在于实现场地自治和数据全局透明共享
C.并行数据库系统经常采用负载平衡方法提供数据库系统的业务吞吐率
D.分布式数据库系统中,不存在全局应用时各局部应用的概念,各节点完全不独立,各个节点需
要协同工作
10.有关系模式A(C,T,H,R,S),其中各属性的含义是:C:课程,T:教员,H:上课时间,R:教室,S:
学生。根据语义有如下函数依赖集F={C→T,(H,R)→C,(H,T)→R,(H,S)→R}。关系模式A的
规范化程度最高达到( )。
A.1NF B.2NF C.3NF D.BCNF
第2讲 数据依赖的公理系统
第一部分 知识点回顾
6.2.7 多值依赖
【例9】学校中某一门课程由多个教师讲授,他们使用相同的一套参考书。每个教员可以讲授多
门课程,每种参考书可以供多门课程使用。
·用二维表表示Teaching
Teaching模式中存在的问题:
(1)数据冗余度大
(2)插入操作复杂
(3)删除操作复杂
(4)修改操作复杂
定义6.9
—58—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
设R(U)是一个属性集U上的一个关系模式,X、Y和Z是U的子集,并且 Z=U-X-Y。关系
模式R(U)中多值依赖 X→→Y成立,当且仅当对R(U)的任一关系r,给定的一对(x,z)值,有一组Y
的值,这组值仅仅决定于x值而与z值无关。
例:Teaching(C,T,B)
对于一个(物理,光学原理)有一组T值{李勇,王军},这组值仅由课程 C上的值(物理)决定,对
于另一个(物理,物理习题集)对应的T值仍是{李勇,王军},因此T多值依赖于C。
·多值依赖的另一个等价的形式化的定义:
在R(U)的任一关系r中,如果存在元组t,s使得t[X]=s[X],那么就必然存在元组 w,v,r,(w,
v可以与s,t相同),使得w[X]=v[X]=t[X],而w[Y]=t[Y],w[Z]=s[Z],v[Y]=s[Y],v[Z]=t
[Z](即交换s,t元组的Y值所得的两个新元组必在 r中),则 Y多值依赖于 X,记为 X→→Y。这里,
X,Y是U的子集,Z=U-X-Y。
元组 课程 教员 参考书
W 物理 李明 物理习题集
T 物理 李明 物理数学方法
S 物理 赵海 物理习题集
V 物理 赵海 物理数学方法
·平凡多值依赖和非平凡的多值依赖
若X→→Y,而Z=φ,则称 X→→Y为平凡的多值依赖;否则称X→→Y为非平凡的多值依赖
用下图表示这种对应
W→→S且W→→C
多值依赖的性质:
(1)多值依赖具有对称性
若X→→Y,则X→→Z,其中Z=U-X-Y
(2)多值依赖具有传递性
若X→→Y,Y→→Z,则X→→Z-Y
(3)函数依赖是多值依赖的特殊情况
若X→Y,则X→→Y
(4)若X→→Y,X→→Z,则X→→Y∪Z
—68—
(5)若X→→Y,X→→Z,则X→→Y∩Z
(6)若X→→Y,X→→Z,则X→→Y-Z,X→→Z-Y。
多值依赖与函数依赖的区别:
(1)多值依赖的有效性与属性集的范围有关
(2)
·若函数依赖X→Y在R(U)上成立,则对于任何Y',Y均有X→Y'成立
·多值依赖X→→Y若在R(U)上成立,不能断言对于任何Y',Y有X→→Y'成立
6.2.8 4NF
·定义6.10 关系模式R<U,F>∈1NF,如果对于R的每个非平凡多值依赖X→→Y(Y X),
X都含有码,则R∈4NF。
·如果R∈ 4NF,则R∈ BCNF
不允许有非平凡且非函数依赖的多值依赖
允许的非平凡多值依赖是函数依赖
6.3 数据依赖的公理系统
逻辑蕴含
定义6.11 对于满足一组函数依赖 F的关系模式R<U,F>,其任何一个关系r,若函数依赖X
→Y都成立,(即r中任意两元组t,s,若t[X]=s[X],则t[Y]=s[Y]),则称F逻辑蕴含X→Y。
1.Armstrong公理系统
关系模式R<U,F>来说有以下的推理规则:
·A1.自反律(Reflexivity):若YX→ U,则X→Y为F所蕴含。
·A2.增广律(Augmentation):若X→Y为F所蕴含,且Z→ U,则XZ→YZ为F所蕴含。
·A3.传递律(Transitivity):若X→Y及Y→Z为F所蕴含,则X→Z为F所蕴含。
定理 6.1 Armstrong推理规则是正确的。
(l)自反律:若YXU,则X→Y为F所蕴含。
证:设YXU
对R<U,F>的任一关系r中的任意两个元组t,s:
若t[X]=s[X],由于YX,有t[y]=s[y],
所以X→Y成立,自反律得证。
(2)增广律:若X→Y为F所蕴含,且ZU,则XZ→YZ为F所蕴含。
证:设X→Y为F所蕴含,且ZU。
设R<U,F>的任一关系r中任意的两个元组t,s:
若t[XZ]=s[XZ],则有t[X]=s[X]和t[Z]=s[Z];
由X→Y,于是有t[Y]=s[Y],所以t[YZ]=s[YZ],所以XZ→YZ为F所蕴含,增广律得证。
(3)传递律:若X→Y及Y→Z为F所蕴含,则 X→Z为 F所蕴含。
证:设X→Y及Y→Z为F所蕴含。
—78—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
对R<U,F>的任一关系 r中的任意两个元组 t,s:
若t[X]=s[X],由于X→Y,有 t[Y]=s[Y];
再由Y→Z,有t[Z]=s[Z],所以X→Z为F所蕴含,传递律得证。
2.导出规则
1)根据A1,A2,A3这三条推理规则可以得到下面三条推理规则:
·合并规则:由X→Y,X→Z,有X→YZ。 (A2,A3)
·伪传递规则:由X→Y,WY→Z,有XW→Z。 (A2,A3)
·分解规则:由X→Y及 Z→Y,有X→Z。 (A1,A3)
2)根据合并规则和分解规则,可得引理6.1
引理6.1 X→A1A2…Ak成立的充分必要条件是X→Ai成立(i=l,2,…,k)
3.函数依赖闭包
定义6.12 在关系模式R<U,F>中为 F所逻辑蕴含的函数依赖的全体叫作 F的闭包,记为 F
+。
定义6.13 设F为属性集 U上的一组函数依赖,X U,XF+ ={A|X→A能由 F根据 Arm
strong公理导出},XF+称为属性集X关于函数依赖集F的闭包。
Armstrong公理系统:
·Armstrong公理系统是有效的、完备的
·有效性:由F出发根据Armstrong公理推导出来的每一个函数依赖一定在F+中;
·完备性:F+中的每一个函数依赖,必定可以由F出发根据Armstrong公理推导出来
F的闭包
关于闭包的引理
·引理6.2
设F为属性集U上的一组函数依赖,X,YU,X→Y能由F根据Armstrong公理导出的充分必
—88—
要条件是YXF+
·用途
将判定X→Y是否能由F根据Armstrong公理导出的问题,转化为求出XF+、判定Y是否为XF+
的子集的问题。
求闭包的算法
算法6.1 求属性集X(XU)关于U上的函数依赖集F的闭包XF
+
输入:X,F
输出:XF
+
步骤:(1)令X(0) =X,i=0;
(2)求B,这里B={A|(V)(W)(V→W∈F∧VX(i)∧A∈W)};
(3)X(i+1) =B∪X(i);
(4)判断X(i+1)=X(i)吗?
(5)若相等或X(i)=U,则X(i)就是XF+,算法终止。
(6)若否,则 i=i+1,返回第(2)步。
对于算法6.1 令ai=|X
(i)|,{ai}形成一个步长大于1的严格递增的序列,序列的上界是 |U
|,因此该算法最多 |U|-|X|次循环就会终止。
4.最小依赖集
定义6.15 如果函数依赖集F满足下列条件,则称F为一个极小函数依赖集。亦称为最小依赖
集或最小覆盖。
(1)F中任一函数依赖的右部仅含有一个属性。
(2)F中不存在这样的函数依赖X→A,使得F与F-{X→A}等价。
(3)F中不存在这样的函数依赖X→A,X有真子集Z使得F-{X→A}∪{Z→A}与F等价。
【例2】设有关系模式S<U,F>,其中:
U={SNO,SDEPT,MN,CNAME,G},
F={SNO→SDEPT,SDEPT→MN,(SNO,CNAME)→G}
设F’={SNO→SDEPT,SNO→MN,
SDEPT→MN,(SNO,CNAME)→G,
(SNO,SDEPT)→SDEPT}
—98—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
第2讲 逻辑与物理结构设计
第一部分 知识点回顾
7.4 逻辑结构设计
1、概念设计的回顾
根据需求分析的结果确定概念模型。
概念模型是对现实世界的一个真实模型,且能满足用户对数据的处理要求。
概念模型直观形象、容易和用户沟通。
概念模型易于修改。
概念模型与具体数据模型无关且容易向数据库模型转化。
2、逻辑结构设计的任务
·概念结构是各种数据模型的共同基础。
·为了能够用某一DBMS实现用户需求,还必须将概念结构进一步转化为相应的数据模型,这正
是数据库逻辑结构设计所要完成的任务。
Sqlserver2000中的表操作界面
—111—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
班名 人数
软051 29
计051 32
… …
姓名 年龄 性别
王洋 27 女
刘兴 32 男
… … …
课名 学时 学分 先修课
数据库 56 3.5 数据结构
操作系统 56 3.5 C语言
… … …
2)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。
①转换为一个独立的关系模式
·关系的属性:与该联系相连的各实体的码以及联系本身的属性。
·关系的候选码:每个实体的码均是该关系的候选码。
例如,独立关系模式:管理(姓名,班名)【详见课程视频】
②与某一端对应的关系模式合并
·合并后关系的属性:加入对应关系的码和联系本身的属性
·合并后关系的码:不变
注意:
·从理论上讲,1:1联系可以与任意一端对应的关系模式合并。
但在一些情况下,与不同的关系模式合并效率会大不一样。因此究竟应该与哪端的关系模式合
并需要依应用的具体情况而定。
·由于连接操作是最费时的操作,所以一般应以尽量减少连接操作为目标。
例如,如果经常要查询某个班级的班主任姓名,则将负责联系与班级关系合并更好些。
(3)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。
①转换为一个独立的关系模式
·关系的属性:与该联系相连的各实体的码以及联系本身的属性。
·关系的码:n端实体的码。
②与n端对应的关系模式合并
·合并后关系的属性:在n端关系中加入1端关系的码和联系本身的属性.
·合并后关系的码:不变
以减少系统中的关系个数,一般情况下更倾向于采用这种方法.
—311—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
例:“负责”联系为1:n联系。将其转换为关系模式的两种方法:
①使其成为一个独立的关系模式:负责(班名,辅导员姓名)
②将其与班级关系模式合并 :负责(班名,人数,辅导员姓名)
(4)一个m:n联系转换为一个关系模式。
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的码:各实体码的组合
例,“开设”联系是一个m:n联系,可以将它转换为如下关系模式,其中班名与课程名为关系的组
合码:
开设(班名,课程名,开课时间)
班名 课名 时间
软051 C语言 2006年春季
软051 数据结构 2006年春季
计061 C语言 2007年秋季
计062 数据结构 2007年秋季
软051 编译原理 2007年春季
(5)三个或三个以上实体间的一个多元联系转换为一个关系模式。
关系的属性:与该多元联系相连的各实体的码以及联系本身的属性
关系的码:各实体码的组合
例,“讲授”联系是一个三元联系,可以将它转换为如下关系模式,其中课程号、职工号和书号为关
系的组合码:
讲授(课程号,职工号,书号)
(6)具有相同码的关系模式可以合并
(7)同一实体集的实体间的联系,即自联系,也可按上述1:1、1:n和m:n三种情况分别处理。
例,如果教师实体集内部存在领导与被领导的1:n自联系,我们可以将该联系与教师实体合并,
这时主码职工号将多次出现,但作用不同,可用不同的属性名加以区分:
教师:{职工号,姓名,性别,职称,系主任}
5、向特定DBMS规定的模型进行转换
·一般的数据模型还需要向特定DBMS规定的模型进行转换。
·转换的主要依据是所选用的DBMS的功能及限制。没有通用规则。
·对于关系模型来说,这种转换通常都比较简单。
6、数据模型的优化
·数据库逻辑设计的结果不是唯一的。
·得到初步数据模型后,还应该适当地修改、调整数据模型的结构,以进一步提高数据库应用系
统的性能,这就是数据模型的优化。
—411—
查询的投影属性
数据更新事务
被更新的关系
每个关系上的更新操作条件所涉及的属性
修改操作要改变的属性值
每个事务在各关系上运行的频率和性能要求
·关系数据库物理设计的内容
(1)为关系模式选择存取方法(建立存取路径)
(2)设计关系、索引等数据库文件的物理存储结构
7.5.2 关系模式存取方法选择
·数据库系统是多用户共享的系统,对同一个关系要建立多条存取路径才能满足多用户的多种
应用要求。
·物理设计的第一个任务就是要确定选择哪些存取方法,即建立哪些存取路径。
·DBMS常用存取方法
索引方法,目前主要是B+树索引方法
聚簇(Cluster)方法
HASH方法
1、索引存取方法的选择
·选择索引存取方法的主要内容
根据应用要求确定
对哪些属性列建立索引
对哪些属性列建立组合索引
对哪些索引要设计为唯一索引
·选择索引存取方法的一般规则
如果一个(或一组)属性经常在查询条件中出现,则考虑在这个(或这组)属性上建立索引(或
组合索引)
如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引
如果一个(或一组)属性经常在连接操作的连接条件中出现,则考虑在这个(或这组)属性上建
立索引
·关系上定义的索引数过多会带来较多的额外开销(维护开销,查找开销)
2、聚簇存取方法的选择
·聚簇的用途
(1)大大提高按聚簇属性进行查询的效率
(2)节省存储空间
·聚簇的局限性
—611—
(1)聚簇只能提高某些特定应用的性能
(2)建立与维护聚簇的开销相当大
·聚簇的适用范围
(1)既适用于单个关系独立聚簇,也适用于多个关系组合聚簇
(2)当通过聚簇码进行访问或连接是该关系的主要应用,与聚簇码无关的其他访问很少或者是次
要的时,可以使用聚簇。
·选择聚簇存取方法
(1)设计候选聚簇
对经常在一起进行连接操作的关系可以建立组合聚簇;
如果一个关系的一组属性经常出现在相等比较条件中,则该单个关系可建立聚簇;
如果一个关系的一个(或一组)属性上的值重复率很高,则此单个关系可建立聚簇。即对应每个
聚簇码值的平均元组数不太少。太少了,聚簇的效果不明显。
(2)检查候选聚簇中的关系,取消其中不必要的关系
从独立聚簇中删除经常进行全表扫描的关系;
从独立/组合聚簇中删除更新操作远多于查询操作的关系;
从独立/组合聚簇中删除重复出现的关系
当一个关系同时加入多个聚簇时,必须从这多个聚簇方案(包括不建立聚簇)中选择一个较优的,
即在这个聚簇上运行各种事务的总代价最小。
3、HASH存取方法的选择
·选择HASH存取方法的规则
当一个关系满足下列两个条件时,可以选择HASH存取方法
该关系的属性主要出现在等值连接条件中或主要出现在相等比较选择条件中
该关系的大小可预知,而且不变;或该关系的大小动态改变,但所选用的 DBMS提供了动态
HASH存取方法。
7.5.3 确定数据库的存储结构
·确定数据库物理结构的内容
1.确定数据的存放位置
影响数据存放位置和存储结构的因素
·硬件环境
·应用需求
存取时间
存储空间利用率
维护代价
这三个方面常常是相互矛盾的
—711—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
例:消除一切冗余数据虽能够节约存储空间和减少维护代价,但往往会导致检索代价的增加。
必须进行权衡,选择一个折中方案。
·基本原则
根据应用情况将
易变部分与稳定部分
存取频率较高部分与存取频率较低部分分开存放,以提高系统性能
2.确定系统配置
·DBMS产品一般都提供了一些存储分配参数
同时使用数据库的用户数
同时打开的数据库对象数
使用的缓冲区长度、个数
时间片大小
数据库的大小
装填因子
锁的数目
等等
7.5.4 评价物理结构
·评价内容
对数据库物理设计过程中产生的多种方案进行细致的评价,从中选择一个较优的方案作为数据
库的物理结构
·评价方法
·定量估算各种方案
存储空间
存取时间
维护代价
·对估算结果进行权衡、比较,选择出一个较优的合理的物理结构
·如果该结构不符合用户需求,则需要修改设计
7.6 数据库实施
·数据库实施的工作内容
用DDL定义数据库结构
组织数据入库
编制与调试应用程序
数据库试运行
—811—
第二部分 考点试题解析
一、综合题【2011年南京航空航天】
1.现有一图书销售数据库,其关系表结构如下:
图书表(图书编号,图书名称,出版社编号,出版社名称,出版时间,出版数量,版次)
图书销售表(图书编号,销售日期,销售数量,书店编号,读者编号,读者姓名,读者电话)
书店表(书店编号,联系电话,所在城市编号,城市名称)
该系统所涉及的数据存在如下约束:
A.一个出版社可以出版多种图书,但一种图书只能在一个出版社出版,在该系统记录的图书出版
社信息中包括图书、出版时间、版次及出版数量信息。
B.一个书店可以出售同种图书的多本给多个读者,每位读者可以从多个书店购买同种图书的多
本,一种图书可以通过多个书店出售多本给同一读者,书店把图书出售给读者后会在系统中记录售书
目录,日期和售书数量信息。
C.一个城市可以有多个书店,但是一个书店只在一个城市有一家店。
问题如下:
1)请根据以上信息用 ER图画出合理的图书销售数据库的概念模型 (4分)
2)以图书销售表为例说明原数据库表设计的不合理之处。(6分)
3)请给出你改进原数据库设计后的图书销售的数据字典 (8分)
4)给出该数据库符合 3NF要求的全部关系模式,并指出关系模式中的全部主码和外码。(6分)
5)在第 4)步的基础上,现按“图书名称”和“出版数量”进行查询,为提高查询效率,需要建立索
引。给出创建索引的两种方法(2分)。选择较合理的一种方法写出其SQL语句 (4分)
第3讲 数据库设计综合考题
2.【2012广东工业大学】请为一个局部应用设计一个数据库,它将保存每个部门及其职工的基本
—911—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
信息。已经通过数据抽象方式获得了两个实体:“职工”和“部门”,一个职工只能属于某一个部门,而
一个部门有多个职工,每个部门都有一个部门经理。其中,职工的基本信息包括:职工工号(ENO)、姓
名(ENAME)、年龄(AGE)、工资(SALARY)和工作部门(DPT);部门的基本信息包括:部门编号
(DNO)、部门名称(DNAME)等。
画出上述实体间的E-R图,并根据E-R图,写出转换后的关系模型(其中1:1,1:n关系均不
换为杜丽的关系模式),并指出每个关系的主键和外键(如果存在的情况下)。
3.根据上述第1题中的基本关系表完成下述各题。
(1)建立一个年龄大于45岁的职工视图EMPV,属性为(DNO,DNAME,ENO,ENAME,AGE,SAL
ARY)。
(2)写出以下查询的关系代数表达式和SQL语句:
检索每个部门经理的工资,要求显示其部门编号、部门名称、经理工号、经理姓名和经理工资。
4.关系数据库设计(20分)【2011青岛大学】
某学校教学单位分院、系两级管理,课程由学院统一设置,学生以系(在实际中对应于专业)为单
位进行管理。现欲开发一教学管理系统,分析得出,该系统由两个子系统构成:课程设置子系统和选
课管理子系统。
对于课程设置子系统,有如下实体:
学院:单位号、单位名、电话、办公地址;
教师:教师号、姓名、性别、职称;
课程:课程号、课程名。
5.要求:一个学院有多个教师,一个教师只能属于一个学院;一个学院可开设多门课程,一门课程
只允许一个学院开设,学院所开设的每门课都要指定开课学期;一个教师可讲授多门课程,一门课程
可由多个教师讲授(注:课程与任课教师可以分属于不同学院),教师讲授的每门课程都有个评价。
对于选课管理子系统,有如下实体:
系:单位号、单位名、电话;
学生:学号、姓名、性别、年龄;
课程:课程号、课程名、学分。
6.要求:一个系有多名学生,一名学生只能属于一个系;一个学生可选修多门课程,一门课程可为
多个学生选修,学生选修的每门课程都有个成绩。
试完成如下工作:
(1)分别设计课程设置和选课管理两个子系统的局部E-R图。(8分)
(2)将上述设计完成的E-R图合并成一个全局 E-R图。要求:学院和系两类实体合并为“单
位”实体,同时显式表达学院和系之间的隶属关系(注:每个学院下设多个系)。(6分)
(3)将该全局E-R图转换为关系模型表示的数据库逻辑结构,并分别使用直下划线和波浪下划
线标明每个关系的主码(或主键)与外码(或外键)。(6分)
7.【2008昆明理工】某图书借阅管理数据库要求提供下述服务:
(a)可通过数据库中保存的出版社名、地址、右边和电话等信息,向有关图书的出版社增购书籍。
—021—
出版社名可唯一标识每个出版社;
(b)可随时查询书库中现有各种图书的书号、书名、库存数量和存放位置。所有每种图书可由书
号唯一标识;
(c)可随时查询借书人的可随时查询借书人的借书证号、姓名和工作部门。借书证号可唯一标识
每个借书人。
其中一个出版社可出版多种图书,同一图书只能由同一个出版社在某一具体的时间出版一定数
量的图书(即出版时间和出版数量):任何借书人可同时借多种图书,任何一种图书可为多个人所借,
在每次借还书时要求登记借书日期和还书日期。
根据以上情况,可补充字段类型等适当信息,作如下设计:
(1)构造该系统的E-R图(要求用字母或数字标识实体间联系的类型,用下划线标识实体的主
关键字);
(2)将E-R模型图转换为等价的关系模型的关系模式(要求用下划线标识实体的主关键字);
(3)用SQL语言定义上述关系模式,要求定义每个模式的主关键字和参照完整性。
8.商场(商场名、经理名)有如下信息:一个商场内有许多柜台(柜台号,柜台名),每个柜台有多
种商品(商品号,价格);每个柜台有多个营业员(工号,姓名,性别);每个营业员卖出许多种商品,一
种商品也可被多位营业员卖出。画出该系统的E-R模型;转化为关系模型;说明转化方法;标出各关
系中的关键字;如果存在外码,标出外码。(15分)【2008湖北工业大学】
9.求针对表:成绩(学号、课程名称、班级,分数)、显示按课程成绩的分析统计表,包括每门课的平
均分、最高分、最低分。(10分)
10.如果针对学生(学号、姓名),成绩(学号,课号,分数),课程(课号,课名)三个数据表有如下查
询:
SELECT学生.学号,姓名 FROM学生,成绩,课程 WHERE学生.学号=成绩.学号 AND成绩.课
号=课程.课号 AND分数>80
试画出用关系代数表示的语法数。再用关系代数表达式优化算法对该语法树进行优化处理,画
出优化后的语法树,根据优化后的语法树写出SELECT语句。(10分)
—121—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
第九章 关系查询处理和查询优化
第一部分 知识点回顾
关系系统的分类
9.1 关系数据库系统的查询处理
9.1.1 查询处理步骤
查询处理步骤
1.查询分析
·对查询语句进行扫描、词法分析和语法分析
·从查询语句中识别出语言符号
·进行语法检查和语法分析
2.查询检查
·根据数据字典对合法的查询语句进行语义检查
—221—
·根据数据字典中的用户权限和完整性约束定义对用户的存取权限进行检查
·检查通过后把SQL查询语句转换成等价的关系代数表达式
·RDBMS一般都用查询树(语法分析树)来表示扩展的关系代数表达式
·把数据库对象的外部名称转换为内部表示
3.查询优化
·查询优化:选择一个高效执行的查询处理策略
·查询优化分类 :
代数优化:指关系代数表达式的优化
物理优化:指存取路径和底层操作算法的选择
·查询优化方法选择的依据:
基于规则(rulebased)
基于代价(costbased)
基于语义(semanticbased)
4.查询执行
·依据优化器得到的执行策略生成查询计划
·代码生成器(codegenerator)生成执行查询计划的代码
9.1.2 实现查询操作的算法示例
1、选择操作的实现
【例1】Select fromstudentwhere<条件表达式>;
考虑<条件表达式>的几种情况:
C1:无条件;
C2:Sno='200215121';
C3:Sage>20;
C4:Sdept='CS'ANDSage>20;
·选择操作典型实现方法:
(1)简单的全表扫描方法
对查询的基本表顺序扫描,逐一检查每个元组是否满足选择条件,把满足条件的元组作为结果输出
适合小表,不适合大表
(2)索引(或散列)扫描方法
适合选择条件中的属性上有索引(例如B+树索引或Hash索引)
通过索引先找到满足条件的元组主码或元组指针,再通过元组指针直接在查询的基本表中找到
元组
【例1-C2】 以C2为例,Sno=‘200215121’,并且Sno上有索引(或Sno是散列码)
使用索引(或散列)得到Sno为‘200215121’元组的指针
通过元组指针在student表中检索到该学生
—321—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
【例1-C3】 以C3为例,Sage>20,并且Sage上有B+树索引
使用B+树索引找到Sage=20的索引项,以此为入口点在B+树的顺序集上得到 Sage>20的所
有元组指针
通过这些元组指针到student表中检索到所有年龄大于20的学生。
【例1-C4】 以C4为例,Sdept=‘CS’ANDSage>20,如果Sdept和Sage上都有索引:
算法一:分别用上面两种方法分别找到 Sdept=‘CS’的一组元组指针和 Sage>20的另一组元组
指针
·求这2组指针的交集
·到student表中检索
·得到计算机系年龄大于20的学生
算法二:找到Sdept=‘CS’的一组元组指针,
·通过这些元组指针到student表中检索
·对得到的元组检查另一些选择条件(如Sage>20)是否满足
·把满足条件的元组作为结果输出。
2、连接操作的实现
·连接操作是查询处理中最耗时的操作之一
·本节只讨论等值连接(或自然连接)最常用的实现算法
【例2】 SELECT FROMStudent,SC
WHEREStudent.Sno=SC.Sno;
(1)嵌套循环方法(nestedloop)
·对外层循环(Student)的每一个元组(s),检索内层循环(SC)中的每一个元组(sc)
·检查这两个元组在连接属性(sno)上是否相等
·如果满足连接条件,则串接后作为结果输出,直到外层循环表中的元组处理完为止
(2)排序-合并方法(sort-mergejoin或mergejoin)
·适合连接的诸表已经排好序的情况
·排序-合并连接方法的步骤:
如果连接的表没有排好序,先对Student表和SC表按连接属性Sno排序
取Student表中第一个Sno,依次扫描SC表中具有相同Sno的元组
排序-合并连接方法示意图
(3)索引连接(indexjoin)方法
—421—
·步骤:
① 在SC表上建立属性Sno的索引,如果原来没有该索引
② 对Student中每一个元组,由Sno值通过SC的索引查找相应的SC元组
③ 把这些SC元组和Student元组连接起来
循环执行②③,直到Student表中的元组处理完为止
(4)HashJoin方法
·把连接属性作为hash码,用同一个hash函数把R和S中的元组散列到同一个hash文件中
·步骤:
划分阶段(partitioningphase):
对包含较少元组的表(比如R)进行一遍处理
把它的元组按hash函数分散到hash表的桶中
试探阶段(probingphase):也称为连接阶段(joinphase)
对另一个表(S)进行一遍处理
把S的元组散列到适当的hash桶中
把元组与桶中所有来自R并与之相匹配的元组连接起来
9.2 关系数据库系统的查询优化
9.2.1 查询优化概述
·查询优化的优点不仅在于用户不必考虑如何最好地表达查询以获得较好的效率,而且在于系
统可以比用户程序的“优化”做得更好。
(1)优化器可以从数据字典中获取许多统计信息,而用户程序则难以获得这些信息
(2)如果数据库的物理统计信息改变了,系统可以自动对查询重新优化以选择相适应的执行计
划。在非关系系统中必须重写程序,而重写程序在实际应用中往往是不太可能的。
(3)优化器可以考虑数百种不同的执行计划,程序员一般只能考虑有限的几种可能性。
(4)优化器中包括了很多复杂的优化技术,这些优化技术往往只有最好的程序员才能掌握。系统
的自动优化相当于使得所有人都拥有这些优化技术。
·RDBMS通过某种代价模型计算出各种查询执行策略的执行代价,然后选取代价最小的执行方
案
集中式数据库
执行开销主要包括:
(1)磁盘存取块数(I/O代价)
(2)处理机时间(CPU代价)
(3)查询的内存开销
I/O代价是最主要的
分布式数据库
总代价=I/O代价+CPU代价+内存代价+通信代价
—521—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·查询优化的总目标:
选择有效的策略
求得给定关系表达式的值
使得查询代价最小(实际上是较小)
实际系统的查询优化步骤
(1)将查询转换成某种内部表示,通常是语法树
(2)根据一定的等价变换规则把语法树转换成标准 (优化)形式
(3)选择低层的操作算法
对于语法树中的每一个操作
·计算各种执行算法的执行代价
·选择代价小的执行算法
(4)生成查询计划(查询执行方案)
·查询计划是由一系列内部操作组成的。
9.3 代数优化
9.3.1 关系代数表达式等价变换规则
·代数优化策略:通过对关系代数表达式的等价变换来提高查询效率
·关系代数表达式的等价:指用相同的关系代替两个表达式中相应的关系所得到的结果是相同
的
·两个关系表达式E1和E2是等价的,可记为E1≡E2
常用的等价变换规则:
(1)连接、笛卡尔积交换律
设E1和E2是关系代数表达式,F是连接运算的条件,则有
(2)连接、笛卡尔积的结合律
设E1,E2,E3是关系代数表达式,F1和F2是连接运算的条件,则有
(3)投影的串接定律
—621—
πA1,A2,…An(πB1,B2,…Bn(E))≡πA1,A2,…An(E)
这里,E是关系代数表达式,Ai(i=1,2,…,n),Bj(j=1,2,…,m)是属性名且{A1,A2,…,An}构成
{B1,B2,…,Bm}的子集。
(4)选择的串接定律
σF1(σF2(E))≡σF1∧F2(E)
这里,E是关系代数表达式,F1、F2是选择条件。
选择的串接律说明选择条件可以合并。这样一次就可检查全部条件。
(5)选择与投影操作的交换律
σF(πA1,A2,…An(E))≡πA1,A2,…An(σF(E))
选择条件F只涉及属性A1,…,An。
若F中有不属于A1,…,An的属性B1,…,Bm则有更一般的规则:
πA1,A2,…An(σF(E))≡πA1,A2,…An(σFπA1,A2,…An(E))
(6)选择与笛卡尔积的交换律
如果F中涉及的属性都是E1中的属性,则
σF(E1×E2)≡σF(E1)×E2
如果F=F1∧F2,并且F1只涉及E1中的属性,F2只涉及E2中的属性,则由上面的等价变换规则1,
4,6可推出:
σF(E1×E2)≡σF1(E1)×σF2(E2)
若F1只涉及E1中的属性,F2涉及E1和E2两者的属性,则仍有
σF(E1×E2)≡σF2(σF1(E1)×E2)
它使部分选择在笛卡尔积前先做。
(7)选择与并的分配律
设E=E1∪E2,E1,E2有相同的属性名,则 σF(E1∪E2)≡σF(E1)∪σF(E2)
(8)选择与差运算的分配律
若E1与E2有相同的属性名,则 σF(E1-E2)≡σF(E1)-σF(E2)
(9)选择对自然连接的分配律
σF(E1E2)≡σF(E1)σF(E2)
F只涉及E1与E2的公共属性
(10)投影与笛卡尔积的分配律
设E1和E2是两个关系表达式,A1,…,An是E1的属性,B1,…,Bm是E2的属性,则
πA1,A2,…,An,B1,B2,…,Bm(E1×E2)≡πA1,A2,…,An(E1)×πB1,B2,…,Bm(E2)
(11)投影与并的分配律
设E1和E2有相同的属性名,则
πA1,A2,…,An(E1∪E2)≡πA1,A2,…,An(E1)∪πA1,A2,…,An(E2)
9.3.2 查询树的启发式优化
典型的启发式规则:
—721—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
1.选择运算应尽可能先做。在优化策略中这是最重要、最基本的一条
2.把投影运算和选择运算同时进行
如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描此关系的同时完成所有
的这些运算以避免重复扫描关系
3.把投影同其前或其后的双目运算结合起来
4.把某些选择同在它前面要执行的笛卡尔积结合起来成为一个连接运算
例:бStudent.Sno=SC.Sno (Student×SC)
5.找出公共子表达式
·如果这种重复出现的子表达式的结果不是很大的关系并且从外存中读入这个关系比计算该子
表达式的时间少得多,则先计算一次公共子表达式并把结果写入中间文件是合算的
·当查询的是视图时,定义视图的表达式就是公共子表达式的情况
·遵循这些启发式规则,应用9.3.1的等价变换公式来优化关系表达式的算法。
算法:关系表达式的优化
输入:一个关系表达式的查询树
输出:优化的查询树
方法:
(1)利用等价变换规则4把形如σF1∧F2∧…∧Fn(E)变换为σF1(σF2(…(σFn(E))…))。
(2)对每一个选择,利用等价变换规则4~9尽可能把它移到树的叶端。
(3)对每一个投影利用等价变换规则3,5,10,11中的一般形式尽可能把它移向树的叶端。
注意:
·等价变换规则3使一些投影消失
·规则5把一个投影分裂为两个,其中一个有可能被移向树的叶端
(4)利用等价变换规则3~5把选择和投影的串接合并成单个选择、单个投影或一个选择后跟一
个投影。使多个选择或投影能同时执行,或在一次扫描中全部完成
(5)把上述得到的语法树的内节点分组。每一双目运算(×,,∪,-)和它所有的直接祖先为
一组(这些直接祖先是(σ,π运算)。
·如果其后代直到叶子全是单目运算,则也将它们并入该组
·但当双目运算是笛卡尔积(×),而且后面不是与它组成等值连接的选择时,则不能把选择与这
个双目运算组成同一组,把这些单目运算单独分为一组
【例4】下面给出[例3]中 SQL语句的代数优化示例。
—821—
(1)把SQL语句转换成查询树,如下图所示
查询树
为了使用关系代数表达式的优化法,假设内部表示是关系代数语法树,则上面的查询树如下图所示。
(2)对查询树进行优化
利用规则4、6把选择σSC.Cno=‘2’移到叶端,查询树便转换成下图所示的优化的查询树。这就是
9.2.2节中Q3的查询树表示
9.4 物理优化
·代数优化改变查询语句中操作的次序和组合,不涉及底层的存取路径
·对于一个查询语句有许多存取方案,它们的执行效率不同,仅仅进行代数优化是不够的
—921—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·物理优化就是要选择高效合理的操作算法或存取路径,求得优化的查询计划
第二部分 考点试题解析
一、综合题
1.学生
"
课程数据库中包含了三个表。
学生表:Student(Sno(学号#),Sname,Ssex,Sage)
学生选课表:SC(Sno,cno(课程号),score)
求选修了2号课程的学生姓名。
假定学生
"
课程数据库中有1000个学生记录,10000个选课记录,其中选修2号课程的选修记录
为50个。
系统可以用多种等价的关系代数表达式来完成这一查询。
1)给出用关系代数表示的上述查询三个查询表达式。(6分)
2)给出查询优化的一般准则。(6分)
3)画出最优的标准语法树。(8分)
2.学生———课程数据库中包含了三个表。(9分)
学生表:student(sno(学号#),sname,ssex,sage)
选课表:sc(sno,cno(课程号),score)
课表:course(cno,coursename,time)
对学生有如下的查询:selectcnamefromstudent,course,scwherestudent.sno=sc.snoandsc.cno=
course.cnoandstudent.sdept=‘IS’;
此查询要求信息系学生选修了的所有课程名称。
1)试画出用关系代数表示的语法树(3分)
2)用关系代数表达式优化算法对原始语法树进行优化,画出优化后的标准语法树。(6分)【2006
太原科技大学,2010沈阳农大】
—031—
第十章 数据库恢复技术
第一部分 知识点回顾
10.1 事务的基本概念
1、事务(Transaction)
·定义
一个数据库操作序列
一个不可分割的工作单位
恢复和并发控制的基本单位
·事务和程序比较
在关系数据库中,一个事务可以是一条或多条SQL语句,也可以包含一个或多个程序。
一个程序通常包含多个事务
2、事务的特性(ACID特性)
(1)原子性:
·事务是数据库的逻辑工作单位
事务中包括的诸操作要么都做,要么都不做
(2)一致性:
·事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态
一致性状态:若数据库中只包含成功事务提交的结果
不一致状态:若数据库中包含失败事务的结果
(3)隔离性
对并发执行而言:一个事务的执行不能被其他事务干扰
·一个事务内部的操作及使用的数据对其他并发事务是隔离的
·并发执行的各个事务之间不能互相干扰
(4)持续性
持续性也称永久性(Permanence)
·一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
·接下来的其他操作或故障不应该对其执行结果有任何影响。
10.2 数据库恢复概述
·破坏事务ACID特性的因素
多个事务并行运行时,不同事务的操作交叉执行
—131—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
事务在运行过程中被强行停止
·故障是不可避免的
系统故障:计算机软、硬件故障
人为故障:操作员的失误、恶意的破坏等。
·数据库的恢复
把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)
·故障的影响
运行事务非正常中断
破坏数据库
·数据库管理系统对故障的对策
DBMS提供恢复子系统
保证故障发生后,能把数据库中的数据从错误状态恢复到某种逻辑一致的状态
保证事务ACID
·恢复技术是衡量系统优劣的重要指标
10.3 故障的种类
·事务内部的故障
有的是可以通过事务程序本身发现的
有的是非预期的(溢出、由于死锁而撤销、违反限制)
·系统故障
·介质故障
·计算机病毒
系统故障
称为软故障,是指造成系统停止运转的任何事件,使得系统要重新启动。
·整个系统的正常运行突然被破坏
·所有正在运行的事务都非正常终止
·不破坏数据库
·内存中数据库缓冲区的信息全部丢失
系统故障的常见原因
·特定类型的硬件错误(如CPU故障)
·操作系统故障
·DBMS代码错误
·系统断电
系统故障的恢复
·发生系统故障时,事务未提交
恢复策略:强行撤消(UNDO)所有未完成事务
—231—
·发生系统故障时,事务已提交,但缓冲区中的信息尚未完全写回到磁盘上。
恢复策略:重做(REDO)所有已提交的事务
·介质故障
称为硬故障,指外存故障
磁盘损坏 ;磁头碰撞;操作系统的某种潜在错误;瞬时强磁场干扰
·介质故障的恢复
装入数据库发生介质故障前某个时刻的数据副本
重做自转储结束时始的所有成功事务,将这些事务已提交的结果重新记入数据库
·计算机病毒
一种人为的故障或破坏,是一些恶作剧者研制的一种计算机程序
·可以繁殖和传播
危害
破坏、盗窃系统中的数据
破坏系统文件
10.4 恢复的实现技术
·恢复操作的基本原理:冗余
利用存储在系统其它地方的冗余数据来重建数据库中已被破坏或不正确的那部分数据
·恢复机制涉及的关键问题
(1)如何建立冗余数据
数据转储(backup)
登录日志文件(logging)
(2)如何利用这些冗余数据实施数据库恢复
10.4.1 数据转储
1、什么是数据转储
·转储是指DBA将整个数据库复制到磁带或另一个磁盘上保存起来的过程,备用的数据称为后
备副本或后援副本
·如何使用
数据库遭到破坏后可以将后备副本重新装入
重装后备副本只能将数据库恢复到转储时的状态
2、转储方法
(1)静态转储与动态转储
静态转储
·在系统中无运行事务时进行的转储操作
·转储开始时数据库处于一致性状态
—331—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
以数据块为单位的日志文件
·以记录为单位的日志文件内容
各个事务的开始标记(BEGINTRANSACTION)
各个事务的结束标记(COMMIT或ROLLBACK)
各个事务的所有更新操作
以上均作为日志文件中的一个日志记录 (log record)
·以记录为单位的日志文件,每条日志记录的内容
事务标识(标明是哪个事务)
操作类型(插入、删除或修改)
操作对象(记录内部标识)
更新前数据的旧值(对插入操作而言,此项为空值)
更新后数据的新值(对删除操作而言,此项为空值)
·以数据块为单位的日志文件,每条日志记录的内容
事务标识(标明是那个事务)
被更新的数据块
2、日志文件的作用
·进行事务故障恢复
·进行系统故障恢复
·协助后备副本进行介质故障恢复
与静态转储后备副本配合进行介质故障恢复
·静态转储的数据已是一致性的数据
·如果静态转储完成后,仍能定期转储日志文件,则在出现介质故障重装数据副本后,可以利用
这些日志文件副本对已完成的事务进行重做处理
·这样不必重新运行那些已完成的事务程序就可把数据库恢复到故障前某一时刻的正确状态
介质故障恢复
介质故障恢复:LOGFILE+动态转储后备副本
·动态转储数据库:同时转储同一时点的日志文件
·后备副本与该日志文件结合起来才能将数据库恢复到一致性状态。
·利用这些日志文件副本进一步恢复事务,避免重新运行事务程序。
—531—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
WHERESUM(Y.take.credit)>=30)
)
FROMxINDepartmen;
【例12-1-7】下面是一些表达式的例子,它们可以作为独立的查询,并且返回相应的结果。
(1)1997
/返回1997/
(2)nil
/返回nil/
(3)NOT(true)
/返回false /
(4)students
/这是student类型的外延,返回所有学生对象/
【例12-1-8】为Person类型创建一实例:
Person(name:”ZhangYi”,birthdate:”02/03/1982”,sex:male)
/上式是个类型为Person的对象表达式,括号中的参数供初始化对象的属性之用,如果提供的
参数不全,可用默认值/
ODL/OQL不是计算完备的语言。它虽然可以独立使用,但要用它开发应用程序,需要与程序设
计语言,例如c++,Smaltalk等相结合。
12.1.3 对象-关系数据库
1、概述
·1999年,sql1999(SQL3)公布,他是继Sql_92后的SQL标准,增加对象功能是其主要特征,被称
为ORDBMS。
·为了与SQL_92及其前驱版本兼容,ORDBMS都保留了表的结构及其有关的语句 ,又定义了一
些面向对象的数据类型 ,最基本的是行类型(rowtype)。
2、行类型
行类型可定义如下:
CREATEROWTYPE<rowtypename>(<componentdeclarations>);
【例12-1-9】定义行类型Person_t和Address_t。
CREATEROWTYPEPerson_t
(name VARCHAR(8),
sex CHAR(2),
bdateDATE,
address REF(Address_t));
CREATEROWTYPEAddress_t
(province CHAR(6),
—261—
city VARCHAR(10),
street VARCHAR(10),
street_no CHAR(4),
apt_n0 CHAR(6),
postcode CHAR(6));
行类型与表类型的区别
行类型与表有质的差别,举其大者有下列诸项:
·表中的行由主键的值来识别,而行类型的对象用系统生成的,惟一的OID来识别;
·表中的属性应遵守第一范式的约束,不能是元组、集合或其他非预定义的类型,而行类型不受
此约束,可以引用任何类型(包括预定义的和非预定义的)作为其分量;
·表通过连接运算才能引用其他元组中的属性,而行类型可以直接通过OID引用其他对象。
行类型数据通过继承定义
要定义学生类型Student_t,可以继承 Person_t中的分量,只须增补学号(sno)和入学日期(enrol_
date)两个分量,参见例12-1-10。
【例12-1-10】定义行类型Student_t。
CREATEROWTYPEStudent_tUNDERPerson_t
(snoCHART(7),
enrol_dateDATE);
行类型同表一样,有四种系统预定义的隐含的操作,即插入对象(INSERT)、删除对象(DE
LETE)、修改对象(UPDATE)和查询(SELECT)。
·插入对象
如果插入对象,首先要构造对象。构造对象可用构造函数。对象构造函数的一般形式为:
<rowtypename>(<componentvalues>)
【例12-1-11】在Person_t中插入一对象。
设某人的地址对象可构造如下:Address_t(‘江苏’,‘南京’,‘珠江路’,‘100’,‘2-301’,’
210018’),则插人某人Person_t对象可用下面的语句:
INSERTINTOPerson_t VALUES(Person_t(‘欧阳美林’,‘女’,1985-06-03,Address_t(‘江
苏’,‘南京’,‘珠江路’,‘100’,‘2-301’,‘210018’)));
·删除对象
【例12-1-12】删除例12-1-11插入的对象。
DElETE
FROMPerson_t
WHEREname=‘欧阳美林’;
执行此语句后,Person_t和Address_t中的相应对象都被删去。但它们的OID不得重用。
·修改对象
【例12-1-13】设欧阳美林迁至珠江路21号1—2,试修改数据库。
—361—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
UPDATEPerson_t
SETaddress.street_no=‘21’,address.apt_no=’1—2’
WHEREname=‘欧阳美林’;
修改后,Person_t和Address_t中被修改对象的OID不变。
·查询
查询用SELECT语句,下面举例说明。
【例12-1-14】 查询学生王义平的学号、入学时间、出生日期和住址的邮政编码。
SELECTsno,enrol_date,bdate,
address.Postcode
FROMStudent_t
WHEREname=‘王义平’;
【例 12-1-15】定义Person_t,Address_t,student_t所对应的表
①表person的定义
CREATETABLEpersonoFTYPEPerson_t
VALUESFORPerson_idARESYSTEMGENERATED,
SCOPEFORaddressISaddr;
上述定义可以创建下面的表:
Person
(name VARCHAR(8),
sex CHAR(2),
bdate DATE,
address REF(Address_t)scopeaddr,
person_id REF(Person_t)systemgenerated)
②表addr的定义
CREATETABLEaddrOFTYPEAddress_t
VALUESFORAddr_idARESYSTEMGENERATED;
上述定义可以创建下面的表:
addr
(province CHAR(6),
city VARCHAR(10),
street VARCHAR(10),
street_no CHAR(4),
apt_no CHAR(6),
postcode CHAR(6),
addr_id REF(Address_t)systemgenerated)
③表studenl的定义
—461—
CREATETABLEstudentOFTYPEStudent_t
VALUESFORStudent_idARESYSTEMGENERATED,
SCOPEFORaddressISaddr;
上述定义可以创建下面的表:
Student
(name VARCHAR(8),
sex CHAR(2),
bdate DATE,
address REF(Address_t)scopeaddr,
sno CHAR(7),
enro_dateDATE,
student_id REF(Student_t)systemgenerated)
第2讲 空间数据库
一、引言
·在许多应用中,事物的空间关系往往成为其主要查询或处理的内容。这些应用有:天文、地理
信息系统(GeographicalInformationsystem,简称GIS)、城市规划、管道和网络系统、交通图、大规模集成
电路版面设计、分子结构图、医学图片等
·面向这类应用的数据库系统必须在常规数据库系统的基础上,增加空间数据类型及其相关的
操作,提供空间索引以及面向查询应用的交互式图形用户界面。经过这样扩充的数据库系统称为空
间数据库系统
从数据管理角度来看,空间数据有下列3个特点:
1.数据量大、结构复杂、关系多样化
2.查询过程比较复杂
3.难以定义多维空间对象的空间次序
空间数据库系统是传统数据库系统的扩充,本章将介绍其主要的扩充部分。这些内容有:
·空间数据模型;
·空间索引;
·空间数据库系统的结构。
二、空间数据模型
1.空间数据类型
在GIS中,空间对象可以抽象成下列3种基本空间数据类型 :
(1)点(POINT)。例如城市。点只表示其空间位置,不表示其范围(extent)。
(2)线(LINE)。例如河流、道路、管道、航线、等高线、等降雨量线、通信或电力线路等。线不但表
—561—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
垂直分割可以通过关系运算“投影”来定义。
例如,有:
WINE(YEAR,NAME,PRODUCER,AREA,COUNTRY)
和WEATHER(YEAR,AREA,COUNTRY,SUN,RAIN)
对 WEATHER可定义两个垂直分片
WEATHER-R:∏YEAR,AREA,COUNTRY,RAIN(WEATHER)
WEATHER-S:∏YEAR,AREA,COUNTRY,SUN(WEATHER)
6.混合分割
可把水平分割和垂直分割这两种方法结合起来使用,产生混合式数据分片。
例如:定义由法国生产的葡萄酒的名称和区域
WINE-F:∏NAME,AREA(σcountry=France(WINE))
3.4 分布式数据库的设计方法
1.DDB设计
(1)数据分片的逻辑设计:从逻辑层面上决定数据分割的原则和方法,并加以实现。
(2)数据分片的位置设计:决定数据分片的物理存放站点,并应该考虑副本的使用及其相关
问题。
(3)LDB设计 与集中式数据库相同
完全指派方法对应的处理调度举例
给定一个系统环境,有2个物理场所phs1,phs2和3个虚拟场所vs1,vs2,vs3。根据应用特点设计
了3个数据分片 F1,F2,F3。他们被首先放在虚拟场所 VS1,VS2,VS3中,涉及的操作有 O1,O2,O3,
O4,O5。具体定义为VS1=<{F1},{O1,O4}>,VS2=<{F2},{O2,O3}>,VS3=<{F3},{O5}
>。包括3个主要事务:
·事物1描述为:在VS1上做O1,把结果传到VS2;在VS2上做O2,把结果传到PHS1。
·事物2描述为:在PHS1上做O4,把结果传到VS3。
·事物3描述为:在VS3上做O5,把结果传到PHS2。则构造处理调度图如下:
未指派下的处理调度示意图
注:边上的数字(i,f,d)分别表示事务、频率和数据传输量
如何指派以减少传输费用呢?可有8种指派。指派1的费用计算如下:
—602—
10×200+10×800+6×800=14800
指派2
6×800=4800
2.分布式数据库设计的原则
对用户来说,分布式系统看起来应当就像非分布式系统一样。
·本地自主性
分布式系统中节点应当是自主的,具体含义为:本地数据是本地占有且本地管理的。本地操作保
持其纯本地性。所有在指定结点上的操作都是由该结点控制的。
·对中心结点没有依赖性
系统中任何结点对于系统的运作都不是必须的,即系统中不应该存在一台中心服务器来提供诸
如事务管理,死锁检测,查询优化和全局系统目录之类的服务。
·连续操作
理想状况下,进行诸如以下情况的操作应该不需要安排关闭系统:
在系统中添加或删除节点;一个或多个节点中动态创建或删除分段。
·位置独立
位置独立等价于位置透明,用户可以访问所有的数据,就像是存储在用户结点上一样。
·分段独立性
用户访问数据和数据分段无关
—702—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
Dataid-d方法是意大利米兰工业大学提出的,它把DDB设计划分成如下五个阶段:
12.6 并行数据库
·并行数据库系统概念
·硬件体系结构
·数据分片技术
·并行性种类
·并行连接
·并行排序
·并行聚合
·为什么并行存取数据?
数据密集型(data-intensive)应用,如决策支持系统、在线处理分析(OLAP)、数据仓库(dataware
house)、知识和数据发现(KDD)等
·并行数据库系统设计的研究问题:并行I/O、并行查询优化、并行性数据库操作等
·定义:以商品化处理机和磁盘为基础的并行系统结构 所支持的数据库系统称为并行数据库系
统
·并行数据库系统的评价参数:
①speedup:对于某个固定的计算任务,1倍计算资源系统所完成的时间与 n倍计算资源所完成时
间之比;理想的speedup曲线为线性加速
②scaleup:1倍计算任务在1倍计算资源系统所完成的时间与n倍计算任务在n倍计算资源系统
所完成时间之比,理想的scaleup曲线为y=1
—902—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·影响并行数据库系统性能的三个因素
①启动代价(startup):启动一个并行操作的代价
②干扰(interference):共享资源之间的相互干扰
③倾斜(skew):一个操作或一个查询可以被分解为若干个可并行执行的子操作或子查询,执行时
间最长的子操作或子查询的响应时间决定该并行操作的响应时间
·实现并行的2种基本技术
①管道
一个操作的输出是另一个操作的输入
②分片
多台机器在不同的数据分片上做相同的事情
·共享内存(SM,SE)
①在SM体系结构中,处理机和磁盘可以通过一个总线来访问一个公共的内存,即所有资源均是
共享的
②处理机间通讯可通过共享内存来进行,比通过通讯机制进行通讯要快得多
—012—
③32或64节点以内并行算法speedup很好
④超过32或64节点以后scaleup很坏,因为所有资源均是共享的,总线或互联网络就变成了一个
瓶颈。超过这个点后增加处理机节点个数没有任何用处,因为处理机不得不化更过的时间来等待总
线并访问内存和磁盘
·共享磁盘(SD)
①所有处理可以直接通过总线或互联访问磁盘,但每个处理机有自己的私有内存
②由于每个处理机有自己的内存,存储器的总线不会成为瓶颈
③提供一定的容错能力,若某处理机或它的内存出问题了,其它处理机可以接管它的任务,因为
数据库驻留在所有处理机可以直接访问的磁盘上。磁盘子系统本身的容错问题可以通过使用 RAID
来解决
④尽管不存在内存共享,共享磁盘仍然成为 SD系统可扩展性问题的障碍,共享的磁盘子系统的
互联成为性能可扩展的瓶颈。SD不能解决可扩展性问题,仅仅缓解了SM系统的可扩展性问题
无共享资源体系结构(SN)
①每个节点由一个处理机、内存和一个或多个磁盘构成
②处理机之间通过高速互联进行通讯
③SN结构克服了SD结构必须通过一个总线进行 I/O操作的缺点,仅仅是对非局部磁盘的存取
才通过网络来进行。
④SN体系结构具有很好的可扩展性,有的甚至可以扩展到成千上万个节点
⑤主要缺点是通讯代价和非局部磁盘的存取代价比较昂贵
—112—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·层次体系结构
①结合了 SN、SM、SD体系结构的特点,在高层看是一个 SN体系结构,但每个节点是由一个 SM
体系结构所构成的。当然每个节点也可是一个SD体系结构
②在这种体系结构中代码的编写是非常复杂的,降低编程复杂度的一种很好的办法是分布式虚
拟存储器体系结构
·循环划分(Round-robin):对于关系r中的第i个元组分配到第(imodn)个磁盘上。该方法保
证了每个磁盘上具有相同数目的元组数。
·哈希分片:关系r中的一个或多个属性作为分片属性,对于r中的元组rt,该元组被分配到第 h
(rt)(0..n-1)个磁盘上。
·范围分片:对于关系r,分片属性为A,则在A上可以定义一个分片向量:[v0,v1,…,vn-2]。
分片过程如下:若t[A]〈v0,则t被分配给第0个磁盘,若t[A]3vn-2,t分配给第n-1个磁盘,若vi
—212—
£t[A]<vi+1,则t被分配给第i+1个磁盘。
分片技术对比
通过三种操作来比较
·扫描整个关系
·点查询:如employee-name=”Campbel”
·范围查询:1000<salary<20000
(1)Round-robin
·对于扫描操作非常好
·但对于点操作和范围操作却不是很好
(2)哈希分片
·对于基于分片属性的点操作是最好的
·如果哈希函数能够保持随即性和均匀性,则哈希分片也能很好的处理扫描操作
·但哈希分片方法不能很好地支持范围查询和基于非分片属性的点查询。
(3)范围分片
·能够很好地支持基于分片属性的点查询和范围查询。但这种支持既具有优点,也具有缺点。
优点是:当一个范围查询只涉及到某几个磁盘时,该查询不必向其他磁盘发出查询请求,这样其
他的磁盘可以响应其他的查询请求,提高了系统的吞吐量;
缺点是:当在某几个磁盘上要存取大量的元组时,这就造成I/O成为瓶颈,造成执行倾斜,从而使
得该查询的响应时间过长。
·如果不产生数据倾斜,范围分片能很好地支持扫描操作
(4)除了round-robin分片处理以外,其他两种分片方法均可能造成倾斜问题。倾斜的分类:
·属性值倾斜:属性值倾斜指的是很多元组在分片属性值上具有相同的元组,这必将导致倾斜。
无论采用范围分片还是哈希分片,属性值倾斜都会导致分片倾斜。
·分片倾斜:分片倾斜指的是在每个片段中的元组个数不同,即使不存在属性值倾斜问题也可能
出现分片倾斜问题。
并行粒度:事物间并行,事务内并行
(1)操作内并行性
多台机器同时执行某个操作(分片技术)
—312—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
(2)操作间并行性
多个操作并发地运行在多台机器上(管道技术)
(3)查询间并行性
不同的查询运行在不同的机器上
·事物间(操作间)并行只能提高系统的吞吐率,不能减少事务的响应时间。故主要讨论事务内
并行。
并行算法
5.1 分片连接
(1)通过范围分片(范围分片向量)或哈希分片方法(哈希函数)将r分片为n个片段,r->r0,r1,
…,rn-1;
(2)通过范围分片或哈希分片方法将s分片为n个片段,s->s0,s1,…,sn-1;
(3)在处理机pi上做子连接操作:ri∞si
仅适合于等连接操作
(1)可使用任何分片方法(包括round-robin)来将r分为n片;
(2)将关系s复制到所有处理机上;
(3)处理机pi执行子连接操作ri∞s。
适合任何形式的连接操作
(1)将关系r分片为m1片:r->r0,r1,…,rm1-1
(2)将关系s分片为m2片:s->s0,s1,…,sm1-1
(3)n=m1m2
(4)将分片ri发送到处理机Pi,0,Pi,1,…,Pi,m2-1
(5)将分片si发送到处理机P0,i,P1,i,…,Pmi-1,i
(6)处理机Pi,j做子连接ri∞si
适合任何形式的连接操作
—412—
(1)分片阶段
·通过范围分片(范围分片向量)或哈希分片方法(哈希函数)将r分片为n个片段
r->r0,r1,…,rn-1
·通过范围分片或哈希分片方法将s分片为n个片段
s->s0,s1,…,sn-1
(2)哈希表建立阶段
在每个树立机pi上,用ri来建立哈希表,使用不同于分片哈希函数的哈希函数
(3)匹配阶段
在每个树立机pi上,用si来匹配哈希表
并行Grace哈希连接、并行Hybrid哈希连接比较复杂
·假定被排序的关系被分放在n个磁盘上,可以采用两种方法来进行排序
(1)并行范围分片排序
(2)并行外部排序
·假定用m个处理机来排序具有n个分片的关系,n<m
(1)使用一个范围分片策略来重分片被排序的关系,使得在范围 i上的的元组被发送给处理机
Pi,并将新的分片临时保存在磁盘Di上。该步是并行执行的,有I/O开销和网络通讯开销
(2)处理机Pi排序存储在磁盘Di上的分片Ri,
(3)合并操作:由于使用的是范围分片,合并操作相当简单,若 i<j,则处理机 Pi上的元祖关键字
值小于处理机Pj上的元组关键字值
(1)局部排序阶段
·每个处理机pi外部排序存储在磁盘Di上的数据,该步是并行执行的
(2)合并每个处理机上的局部排序结果:
—512—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
·每个处理机上排序后的分片进一步被范围分片到m个处理机上,这些元组以排序序来发送
·每个处理机当收到来自其他处理机上的元组时进行合并操作
·某个处理机最后合并所有处理机上的合并结果,这个合并非常简单
集中式二阶段并行聚合算法
层次合并的并行聚合算法
两阶段并行聚合算法
再分布并行聚合算法
·局部聚合阶段
它是在各个节点上进行一个集中式聚合操作
·集中合并阶段
各个局部聚合结果都发送到一个中央节点(称为协调者)进行最后的全局合并并生成最终的全局
聚合结果
·优点
当GroupBy子句的选择率比较小的时候,由于各个局部聚合结果的聚合组数较少,这样就减少了
算法的通信开销,从而提高了算法的性能
·缺点
但是随着GroupBy子句选择率的不断增加,通信开销也将随之增加,而且由于局部聚合的聚合组
数的增大,中央协调者的工作负载也就越来越重,并最终可能成为并行算法的性能瓶颈
·局部聚合阶段
与集中式二阶段并行聚合算法相类似
·层次合并阶段
与集中式二阶段并行聚合算法不同,不是将各个节点的聚合结果发送到一个中央协调者,而是分
层次并行地进行部分聚合结果的合并,并得到中间合并结果,这些中间结果可能被进一步并行地合并
为新的中间结果或者合并为一个全局聚合结果
该算法在性能上作了改进,减轻了合并节点的工作负担,但它并不能最终解决性能瓶颈问题,因
为当GroupBy子句的选择率足够大时,层次合并阶段亦会成为该算法的性能瓶颈,只是该算法性能瓶
颈的出现比集中式二阶段并行聚合算法来得晚些
·局部聚合阶段
在这个阶段各个局部节点在各自的节点上进行集中式的聚合操作,并将局部聚合结果通过选择
一个哈希函数作用到GroupBy属性上将局部聚合结果散列到各个节点上
·全局聚合阶段
这个阶段主要是合并被散列到该节点上的局部聚合结果
·由于对局部聚合结果进行了重新散列,所以全局聚合阶段的聚合结果不需要进行合并,这样全
局聚合阶段是在各个节点上并行进行的,避免了前两种算法的性能瓶颈问题
·再分布并行聚合算法
基本思想:先将r的每个子分片通过选择一个哈希函数并作用到GroupBy属性值上,将这些元组
—612—
再分布到不同的节点上。
在每个节点上有一个聚合操作,该操作接收再分布操作符发送过来的元组并进行聚合操作
由于对来自于聚合操作组的输入元组直接进行了散列,所以各个节点的聚合操作结果不需要进
行合并。
(a)再分布并行聚合算法散列的是各个局部分片或聚合操作的输入,而两阶段并行聚合算法散列
的是各个局部聚合结果,也就是说前者在网络中传输的是子分片中的元组,而后者传输的是局部聚合
的结果元组,因而后者的网络通信开销较少;
(b)两阶段并行聚合算法有两级聚合操作,即局部聚合操作和全局聚合操作,而再分布并行聚合
算法只有一级聚合操作;
(c)当GroupBy子句的选择率很低时,使得再分布并行算法在初始散列之后,由于分组数少可能
造成有些处理机没分配到任务而处于空闲,而使处理机的利用率较低;
(d)当GroupBy子句的选择率高时,两阶段并行算法性能不如再分布算法。
因为两阶段并行聚合算法在进行局部聚合时,对于同一分组属性在不同的节点内存中都可能有
其局部聚合结果的入口;而再分布并行聚合算法进行散列后,每个分组属性在系统中只存在一个聚合
结果。所以两阶段并行聚合算法对内存总的占用量较大,使某些节点发生内存不足而需要进行额外
的I/O操作,尤其随GroupBy的选择率的增大,I/O操作也增加,两阶段并行聚合算法性能也迅速下
降。而再分布并行聚合算法不需要局部聚合操作,也不会由于内存不足而进行I/O操作,因此其性能
将越来越好。因此当选择率超过某一值后,再分布并行聚合算法的性能要优于两阶段并行聚合算法。
—712—
王珊、萨师煊《数据库系统概论》考研要点强化及真题解析
高速下载:
点击后进入安全下载页,再进行实际下载。下载链接有效期 24 小时,过期会自动刷新。



 WMS仓库系统
WMS仓库系统